当前位置:
X-MOL 学术
›
WIREs Data Mining Knowl. Discov.
›
论文详情
Our official English website, www.x-mol.net, welcomes your feedback! (Note: you will need to create a separate account there.)
A survey on datasets for fairness-aware machine learning
WIREs Data Mining and Knowledge Discovery ( IF 7.8 ) Pub Date : 2022-03-03 , DOI: 10.1002/widm.1452 Tai Le Quy 1 , Arjun Roy 1, 2 , Vasileios Iosifidis 1 , Wenbin Zhang 3 , Eirini Ntoutsi 2
WIREs Data Mining and Knowledge Discovery ( IF 7.8 ) Pub Date : 2022-03-03 , DOI: 10.1002/widm.1452 Tai Le Quy 1 , Arjun Roy 1, 2 , Vasileios Iosifidis 1 , Wenbin Zhang 3 , Eirini Ntoutsi 2
Affiliation
|
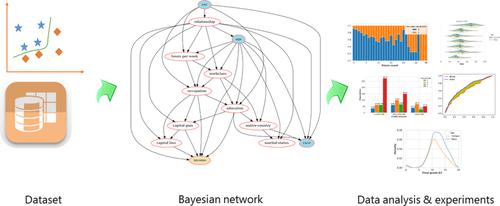
As decision-making increasingly relies on machine learning (ML) and (big) data, the issue of fairness in data-driven artificial intelligence systems is receiving increasing attention from both research and industry. A large variety of fairness-aware ML solutions have been proposed which involve fairness-related interventions in the data, learning algorithms, and/or model outputs. However, a vital part of proposing new approaches is evaluating them empirically on benchmark datasets that represent realistic and diverse settings. Therefore, in this paper, we overview real-world datasets used for fairness-aware ML. We focus on tabular data as the most common data representation for fairness-aware ML. We start our analysis by identifying relationships between the different attributes, particularly with respect to protected attributes and class attribute, using a Bayesian network. For a deeper understanding of bias in the datasets, we investigate interesting relationships using exploratory analysis.
中文翻译:

公平感知机器学习数据集调查
随着决策越来越依赖机器学习(ML)和(大)数据,数据驱动的人工智能系统的公平性问题越来越受到研究和工业界的关注。已经提出了各种各样的公平感知 ML 解决方案,其中涉及对数据、学习算法和/或模型输出的公平相关干预。然而,提出新方法的一个重要部分是在代表现实和多样化设置的基准数据集上对它们进行经验评估。因此,在本文中,我们概述了用于公平感知 ML 的真实数据集。我们将表格数据作为公平感知机器学习最常见的数据表示形式。我们通过识别不同属性之间的关系开始我们的分析,特别是关于受保护的属性和类属性,使用贝叶斯网络。为了更深入地了解数据集中的偏差,我们使用探索性分析来调查有趣的关系。
更新日期:2022-03-03
中文翻译:
公平感知机器学习数据集调查
随着决策越来越依赖机器学习(ML)和(大)数据,数据驱动的人工智能系统的公平性问题越来越受到研究和工业界的关注。已经提出了各种各样的公平感知 ML 解决方案,其中涉及对数据、学习算法和/或模型输出的公平相关干预。然而,提出新方法的一个重要部分是在代表现实和多样化设置的基准数据集上对它们进行经验评估。因此,在本文中,我们概述了用于公平感知 ML 的真实数据集。我们将表格数据作为公平感知机器学习最常见的数据表示形式。我们通过识别不同属性之间的关系开始我们的分析,特别是关于受保护的属性和类属性,使用贝叶斯网络。为了更深入地了解数据集中的偏差,我们使用探索性分析来调查有趣的关系。






























 京公网安备 11010802027423号
京公网安备 11010802027423号