Nature Machine Intelligence ( IF 23.8 ) Pub Date : 2024-02-23 , DOI: 10.1038/s42256-024-00791-0 Carlos Outeiral , Charlotte M. Deane
|
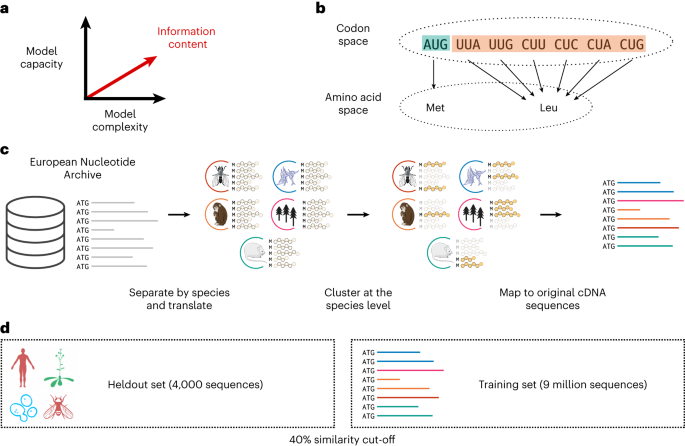
Protein representations from deep language models have yielded state-of-the-art performance across many tasks in computational protein engineering. In recent years, progress has primarily focused on parameter count, with recent models’ capacities surpassing the size of the very datasets they were trained on. Here we propose an alternative direction. We show that large language models trained on codons, instead of amino acid sequences, provide high-quality representations that outperform comparable state-of-the-art models across a variety of tasks. In some tasks, such as species recognition, prediction of protein and transcript abundance or melting point estimation, we show that a language model trained on codons outperforms every other published protein language model, including some that contain over 50 times more parameters. These results indicate that, in addition to commonly studied scale and model complexity, the information content of biological data provides an orthogonal direction to improve the power of machine learning in biology.
中文翻译:
密码子语言嵌入为蛋白质工程提供了强大的信号
来自深度语言模型的蛋白质表示已经在计算蛋白质工程的许多任务中产生了最先进的性能。近年来,进展主要集中在参数计数上,最近模型的容量超过了它们所训练的数据集的大小。在这里我们提出一个替代方向。我们证明,在密码子而不是氨基酸序列上训练的大型语言模型提供了高质量的表示,在各种任务中都优于同类最先进的模型。在某些任务中,例如物种识别、蛋白质和转录本丰度预测或熔点估计,我们表明,基于密码子训练的语言模型优于所有其他已发布的蛋白质语言模型,包括一些包含超过 50 倍参数的模型。这些结果表明,除了普遍研究的规模和模型复杂性之外,生物数据的信息内容为提高生物学中机器学习的能力提供了正交方向。































 京公网安备 11010802027423号
京公网安备 11010802027423号