Nature Machine Intelligence ( IF 23.8 ) Pub Date : 2024-04-23 , DOI: 10.1038/s42256-024-00820-y Hannah Rose Kirk , Bertie Vidgen , Paul Röttger , Scott A. Hale
|
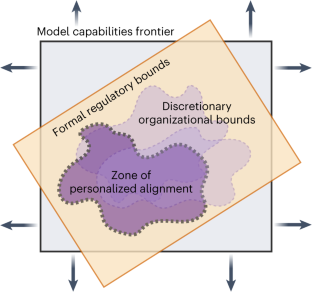
Large language models (LLMs) undergo ‘alignment’ so that they better reflect human values or preferences, and are safer or more useful. However, alignment is intrinsically difficult because the hundreds of millions of people who now interact with LLMs have different preferences for language and conversational norms, operate under disparate value systems and hold diverse political beliefs. Typically, few developers or researchers dictate alignment norms, risking the exclusion or under-representation of various groups. Personalization is a new frontier in LLM development, whereby models are tailored to individuals. In principle, this could minimize cultural hegemony, enhance usefulness and broaden access. However, unbounded personalization poses risks such as large-scale profiling, privacy infringement, bias reinforcement and exploitation of the vulnerable. Defining the bounds of responsible and socially acceptable personalization is a non-trivial task beset with normative challenges. This article explores ‘personalized alignment’, whereby LLMs adapt to user-specific data, and highlights recent shifts in the LLM ecosystem towards a greater degree of personalization. Our main contribution explores the potential impact of personalized LLMs via a taxonomy of risks and benefits for individuals and society at large. We lastly discuss a key open question: what are appropriate bounds of personalization and who decides? Answering this normative question enables users to benefit from personalized alignment while safeguarding against harmful impacts for individuals and society.
中文翻译:
将大型语言模型与个人进行个性化匹配的好处、风险和界限
大型语言模型(LLM)经过“调整”,以便更好地反映人类价值观或偏好,并且更安全或更有用。然而,协调本质上是困难的,因为现在与法学硕士互动的数亿人对语言和对话规范有不同的偏好,在不同的价值体系下运作并持有不同的政治信仰。通常,很少有开发人员或研究人员规定对齐规范,从而冒着各个群体被排除或代表性不足的风险。个性化是法学硕士发展的新领域,模型是针对个人量身定制的。原则上,这可以最大限度地减少文化霸权、增强实用性并扩大准入范围。然而,无限制的个性化会带来大规模分析、隐私侵犯、偏见强化和弱势群体剥削等风险。定义负责任的和社会可接受的个性化的界限是一项艰巨的任务,面临着规范性的挑战。本文探讨了“个性化调整”,即法学硕士适应用户特定的数据,并重点介绍了法学硕士生态系统最近向更大程度的个性化方向的转变。我们的主要贡献是通过对个人和整个社会的风险和收益进行分类,探讨个性化法学硕士的潜在影响。最后我们讨论一个关键的开放性问题:个性化的适当界限是什么以及由谁决定?回答这个规范性问题使用户能够从个性化调整中受益,同时防止对个人和社会产生有害影响。






























 京公网安备 11010802027423号
京公网安备 11010802027423号