
Abstract
The main objective of this paper is to develop quantitative measures for describing the diversity, homogeneity, and similarity of archaeological data. It presents new approaches to characterize the relationship between archaeological assemblages by utilizing entropy and its related attributes, primarily diversity, and by drawing inspiration from ecology. Our starting premise is that diachronic changes in our data provide a distorted reflection of social processes and that spatial differences in data indicate cultural distancing. To investigate this premise, we adopt a parsimonious approach for comparing assemblage profiles employing and comparing a range of (Hill) diversities, which enable us to exploit different aspects of the data. The modelling is tested on two seemingly large datasets: a Late Bronze Age Cretan dataset with circa 13,700 entries (compiled by PG); and a 4th millennium Western Tripolye dataset with circa 25,000 entries (compiled by AD). The contrast between the strongly geographically and culturally heterogeneous Bronze Age Crete and the strongly homogeneous Western Tripolye culture in the Southern Bug and Dnieper interfluve show the successes and limitations of our approach. Despite the seemingly large size of our datasets, these data highlight limitations that confine their utility to non-semantic analysis. This requires us to consider different ways of treating and aggregating assemblages, either as censuses or samples, contingent upon the degree of representativeness of the data. While our premise, that changes in data reflect societal changes, is supported, it is not definitively confirmed. Consequently, this paper also exemplifies the limitations of large archaeological datasets for such analyses.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
Introduction
Computational advances over the last decade have led to new digital approaches for the collection, storage, and analysis of archaeological data. In noting this paradigm shift in archaeology through what he termed the Third Science Revolution, Kristiansen (2014, 2022) considered the possibility of accessing ‘big archaeological data’, with the potential of revealing macro-archaeological patterns (e.g. Mesoudi 2011; Perreault 2019). What ‘big data’ means and how we should quantify and conceptualize it remains up for debate (Huggett, 2020; VanValkenburgh & Dufton, 2020). Certainly, the ‘big data’ collected by large media corporations dwarfs anything currently present in archaeology. The Southwest Social Networks (SWSN) Project represents one exception, with a collected ceramic database of over 4.3 million artifacts (Mills et al., 2015). In the present paper, we rely on two, much smaller ceramic datasets. The first, with circa 13,700 entries incorporates ceramics from Late Bronze Age Crete (LBA), while the second with circa 25,000 entries represents ceramics from the Western Tripolye Culture dated to the 4th millennium. Neither dataset can be considered ‘big data’, but their size is quite typical of quantified ceramic datasets in archaeology. Consequently, it might be more accurate to refer to such collections as ‘lots of data’. The difference between the two lies in the statistical representativeness of the latter, whose data management is subject to systemic, human errors that can be highly correlated with excavation efforts, and whose publication processes often favour easily identifiable examples.
Although the digitisation of archaeological material has made cross-site comparison of ceramic data easier, its collection remains fraught with difficulties. Many early twentieth century excavations, for example, favoured the collection and recording of complete, fine-ware vessels at the expense of more fragmentary, coarse, or semi-coarse examples (e.g. Gheorghiade, 2020). Consequently, their publication is presented as illustrative of uncovered artifacts associated with specific spaces or strata, not amenable for quantification. More recent publications curate their selection into catalogues that include representative examples of recovered ceramic types, rather than statistically representative samples of the available or excavated material.
We forefront the variability of assemblages in our analysis as we believe that patterns represented by the rise and fall in variability (e.g. unification – diversity – unification) can be found in a range of datasets from varying periods and regions. Such repetitive patterns may reflect social change (Gronenborn et al., 2017; Diachenko & Sobkowiak-Tabaka, 2022). In this paper, we explore the extent to which our ceramic datasets open themselves to a similar analysis, considering that, historically, this is something we might have anticipated. We also consider the extent to which spatial variations may reflect cultural separation.
So, how can variability be studied in incomplete archaeological assemblages? We explore this question by proposing new quantitative tactics for characterizing archaeological data. Specifically, our focus is on developing quantitative measures for describing the diversity, homogeneity, and similarity of archaeological data, calling upon information-theoretic ideas to identify patterns in cultural change. We intentionally take an approach that, a priori, prioritizes non-narrative perspectives through inductive data-modelling. Throughout this paper our modelling strategy remains one of parsimony. We work with the most limited categorisation of the data and the most limited analysis that can still permit useful outcomes. This broad-brush approach means that, when the modelling fails, as it will, our outcomes can still tell us something useful about the data that we may not have noticed, or help support suppositions that we may hold for other reasons.
Although our title refers to ‘information’ its colloquial use is here reflected only partially. Our more specific use of ‘information’, encoded through entropy, begins with the work of Shannon (1948) and is now part of mainstream data analysis. There is significant information-inspired archaeological literature effectively invoking entropy that is a precursor to our approach (e.g. Bevan et al., 2013; Barjamovic et al., 2019; Crema, 2015; Diachenko et al., 2020, 2022; Dickens and Fraser, 1984; Drost & Vander Linden, 2018; Furholt, 2012; Gjesfjeld et al., 2020a, 2020b; Gronenborn et al., 2014, 2017, 2018, 2020; Kandler & Crema, 2019; Neiman, 1995; Paige & Perreault, 2022; Premo & Kuhn, 2010; Shott, 2010; Hegmon et al., 2016; Wiśniewski et al., 2022), but in some cases, internal consistency is not clear.
Issues regarding consistency in defining assemblages were largely resolved earlier this century by ecologists (see Jost, 2006, 2007; Chao et al., 2012, 2014), who converted ‘information’ into the much more pragmatic diversity. Our approach is akin to that of Colwell and Chao (2022) and in line with the most recent compilations on diversity in archaeology that call upon ecological methodology (see Eren et al., 2022). We examine the diversity of a LBA dataset by applying a range of measures, including Shannon diversity, and generalized (q-number) Hill diversities, with tactics for exploring aggregation. We also consider spatial variation, measured by homogeneity, through β-Diversity, which reduces to several familiar similarity indices, e.g. Jaccard and Morisita-Horn.
Measuring change in assemblage composition is difficult, especially with imperfect data containing gaps and inaccuracies in labelling. The application of different Hill diversities allows us to emphasise various common and uncommon aspects in the data, while aggregation methods assist in overcoming poor statistics with larger data sets. Overall, measuring change requires a combination of theoretical and practical error analyses from which, nonetheless, we can draw some useful conclusions.
With entropy as the core ingredient of diversity, it is the source of our use of the term ‘entropology’. Our use here differs from its earlier, more colloquial application by Lévi-Strauss (1955, 1961: 397) as a conflation of entropy and anthropology, with the familiar trope of increasing entropy as disorder. Entropy, as disorder, is only valid for closed systems and our systems of migration and exchange are very open. We are primarily interested in an end of cycle reduction, rather than an increase in entropy, making these usages of ‘entropology’ wholly complementary.
Curation as Translation
We take ‘translation’ as a useful metaphor when relating artefacts to the population that produced them. Like social media data, archaeological data are dynamic products of material culture of the society that created them, changing in time and varying with place in response to human actions (Schiffer, 1987). From a historic understanding of information (Shannon, 1948), a viewpoint commensurate with the algorithmic approach of big data companies, we consider our archaeological datasets as output messages from cultural inputs delivered via a noisy communication channel whose code we do not understand (Justeson, 1973; see also see Nolan, 2020). Our work here is one step removed, but to keep the metaphor in part, our data are not messages equated with telephone conversations, but more like the roar of a crowd at a football match. Does the roar of the crowd change as the season develops (e.g. due to a change in management)? Does it differ for home and away matches? How would we know? We were inspired by the earlier work of Gronenborn et al., (2014, 2017, 2018, 2020) and Diachenko et al. (2020) and their success in using memoryless changes in ceramic assemblages as a proxy for patterns in cultural change in early European farming societies. These earlier papers used Shannon entropy, as a diversity index and a touchstone, which here we generalise to Hill diversity in a way that is familiar to ecologists (Colwell & Chao, 2022; Jost, 2006, 2007) and mathematicians.
We adopt a weaker premise within this metaphor of ‘telephony’ that, irrespective of our inability to understand the ‘code’, diachronic change in our dataset outputs arise because of diachronic change in cultural inputs. Since ‘culture’ is a slippery concept, here we are only using it in the very limited sense of attaining a certain level of similarity, which is all we need for categorising artefacts (see Furholt, 2012).
We suggest that changes in data permit a ‘translation’ of these patterns of cultural change, albeit partial and distorted due to data limitations. Changes in data patterns may reflect social transformations (reflective cycles) (e.g. Gronenborn, et al., 2017) or may not (self-organized cycles) (Diachenko & Sobkowiak-Tabaka, 2022). For the latter, we consider cycles akin to changes in fashion rather than a revolution, although it is quite possible that both tendencies are present. To discriminate between the two, one requires contextual information beyond the data itself (e.g. the importance of climate change in Gronenborn, et al., 2017). Therefore, in addition to diachronic differences in our data, we shall also consider synchronous spatial heterogeneity (Courmier et al., 2018). Two modern examples highlight our point: changes in skirt length in western Europe and North America in the 1960’s and the wearing of blue jeans. For some women, particularly in major cities where short skirts were part of a much wider cultural ‘revolution’, they were a marker of social transformation. For others, particularly in small towns away from the heat of political argument, they were just a welcome change of fashion (see Hillman, 2013, 163). Its European counterpart is the role of blue jeans as both a fashion and a political statement (see Levi Strauss & Co© in Panek, 2019).
What is very clear is that the diversity of the assemblage depends, in detail, on the categorization scheme. We have assumed a common ‘core’ of morphological categories, including the most frequently populated; however, we are not interested in absolute values of diversity but rather the direction of its change. Our assumption is that all ‘reasonable’ categorizations could identify a rise or fall in diversity with greater or less efficiency if it were present. This is, in the first instance, the level of our quantitative analysis.
The lack of standardization in nomenclature (Hallager & Hallager, 1997), especially for excavated artifacts from the same cultural horizon, presents a challenge for data standardization needed for database integration, analysis, and cross-geographical comparisons (Gheorghiade, 2020). Although taxonomical construction in archaeology is period and site specific, we assume a common ‘core’ lexicon of morphological categories (Lyman & O’Brien, 2003; O’Brien & Lyman, 2000). Essentially, the idea is to replace our myriad artefact attributes by the low-dimensional labels that they would possess if, for example, they were on display in a museum. These label-entries are chosen to convey their fundamental attributes, taken from a limited vocabulary. Every artefact assemblage is now represented by a ‘label-heap’ which we can ‘read’, with the problem reducing to how we read and compare such label-heaps. We know how reductionist this approach is when we find our favourite artefacts on loan with nothing but the labels to remind us, but we argue that for the purpose of identifying changes and differences, such limited labelling is sufficient. The taxonomic categories assigned to artefacts provide us with the first relatively high taxonomic level entry, e.g. jug, cup. This entry, the most important in our analysis, provides the ‘words’ used for word-frequency analysis that will be initially used as a cultural proxy. In this paper, we take a coarse-grained approach and ignore the presence or absence of decorative elements (Diachenko et al., 2020).
With the goal of comparing assemblages, we need to identify quantitative changes in the data. We can consider assemblages in two ways depending on whether we think of them as censuses or as samples (Orton, 2000). An assemblage thought of as a census (the observed assemblage), e.g. vessels on a table, can be thought as ‘what you see is what you get’. On the other hand, an assemblage thought of as a sample (the effective assemblage) is deemed statistically representative of a virtual assemblage of arbitrarily large size, i.e. the assemblage that we might have constructed had we more time and money to do so. It will carry statistical uncertainty (e.g. see Turing as discussed by Good (1953).
Likewise, there are two corresponding approaches to aggregation. The first, census aggregation, also known as landscape aggregation from its use in ecology (Jost, 2006), corresponds to physically putting assemblages together as censuses, e.g. combining two small tables of ceramics (or photographs) into a larger table (see Fig. 2). Relative assemblage size matters and adding a smaller assemblage to a larger one will not significantly alter the statistics. The second, effective aggregation, treats each sub-assemblage as a sample from a larger ‘undiscovered’ assemblage. Therefore, by aggregating a small assemblage with a large assemblage it is possible to extrapolate the smaller assemblage until it is the same size as its larger counterpart, albeit with inevitable uncertainty. Equivalently, as rarefaction the number of individuals in the larger sample is reduced, the proportions are preserved (Sanders, 1968). Statistically, the effect is that all assemblages are given equal weight and/or status.
Prehistoric Ceramics as Datasets
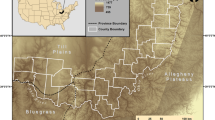
There is a tension between the universality of the conceptual and technical toolkits that we bring to bear on the data and the specificity of the data and the cultures from which it arises. Our paper uses two very different datasets from very different geographical environments to illuminate this tension (Fig. 1). Different landscapes and environments impact the distance between sites, often used as a proxy for considering interaction in archaeology (e.g. Lipo et al., 2015). The Western Tripolye sites in the Southern Bug and Dnieper interfluve lie in a homogeneous plain, whereas the Cretan sites are heterogeneous coastal sites surrounded by a mountainous interior. This helps account for some of the homogeneity of the data in the former and the heterogeneity of the data in the latter.

© 2023 Google Satellite [basemap]
Western Tripolye Culture (WTC) Ceramics
This dataset, discussed in more detail elsewhere by Diachenko et al. (2020), consists of Western Tripolye Culture (WTC) ceramics from the Southern Bug and Dnieper interfluve dated to 4100–3600 BCE. It includes c. 25,000 ceramic fragments—where each fragment, restored or complete vessel is counted as one artefact—as well as restored or complete vessels analysed by Sergej Ryzhov. The WTC population arrived in the region circa 4100 BCE. This area is widely known in this period for its mega-sites, hosting the largest population agglomeration in Neolithic Europe. Around 3600 BCE, settlements began to decrease in size, and this decrease was accompanied by a significant change in the ceramic complex (see Ryzhov, 2021 & earlier papers). The evidence suggests that the Cucuteni-Tripolye populations burnt their dwellings. House-burning, often understood as a ‘dwelling’s burial’, was preceded by various ritual actions, including the destruction of ovens and, what is important for us here, specific placement of previously used vessels inside houses (Kruts, 2003). Thus, ceramic assemblages of WTC houses simultaneously represent settlement and ‘funerary’ contexts which compress the gradual changes in pottery styles over a settlement’s duration.
The 500-year period spanning 4100–3600 BCE can be subdivided into 10 ‘analytical periods’ of approximately equal duration. This chronology is based on the frequency seriation and occurrence seriation of vessel ornamentation styles (Ryzhov, 2012), later delineated with the application of spatial statistics (Diachenko & Menotti, 2012). This chronological scheme finds its confirmation in recently obtained AMS radiocarbon dates (Harper, 2021; Harper et al., 2021). Therefore, taken as ‘single events’, our ten ‘analytical periods’ capture relocation of people in the analysed region. Aided by the relatively homogeneous physical environment, the ceramic assemblages from different synchronous sites across the region are remarkably similar in composition. They highlight differences in pottery shapes and ornamentation at high taxonomic levels of only a few percent (Ryzhov, 2021). Although they account for only circa 5% of the excavated data, the sample of 25,000 ceramic fragments and complete vessels is representative of the circa 500,000 entities from this region as analysed by Sergej Ryzhov. The following core categorisation of artefacts shows that a lexicon of 13 categories (wordlist) is sufficient (see Ryzhov, 2012):
‘Goblet’, ‘Goblet-shaped’, ‘Sphere-conical’ and ‘biconical’, ‘Amphora’, ‘Pear-shaped’, ‘Lid’, ‘Krater’ and ‘Krater-shaped’, ‘Pot’, ‘Binocular-shaped’, ‘Ladle’ and ‘vessels on trays’
Even with these categories, some care is necessary. Bowls were deliberately excluded from the WTC analysis since the WTC ceramics are fragmentary. Small fragments of bowls are more easily distinguished typologically than ceramic fragments of other types. Therefore, if bowls are included in the estimations, the overall distribution may be biased. Nonetheless, the structured data deposition from house ‘burials’ together with the homogeneity of mega-sites makes the WTC ceramics an idealised dataset (for a more detailed analysis see Diachenko et al., 2020).
Late Bronze Age Cretan Ceramics
Our second dataset comprises a collection of more than 13,700 ceramics compiled from published excavation catalogues (Gheorghiade, 2020). These ceramics date to the Late Bronze Age (LBA) and were recovered and recorded as part of excavations carried out across Crete at the sites of Chania, Kommos, Knossos, Mochlos, and Palaikastro (Fig. 1b). Over the last century, the recovery of such large quantities of complete and restorable ceramics from across the island has resulted in the development of typologies based on their functional criteria (Knappett, 2022: 118). These capture both the shape and potential function of the vessel, providing a classificatory system that supports cross-temporal, cross-spatial, and cross-cultural comparisons.
The ceramics in this dataset span a 250-year period (roughly 1450–1200 BCE) during which Crete became increasingly more connected in the eastern and western Mediterranean. Archaeologically, we may associate the spread of mainland Greek material culture on Crete, more generally labelled by ‘Mycenaeanization’, as a single ‘event’; however, this transformation was more gradual, and the result of a complex set of processes that led to the adoption, incorporation, and transformation of new traditions and ceramics into Cretan assemblages.
Material from this highly connected period is difficult to separate, identify, and characterize. What are often thought of as ‘Minoan’ or ‘Mycenaean’ cultural characteristics based on the surviving archaeological evidence must also be acknowledged as largely modern constructs (D’Agata et al., 2005: 14). The social and cultural influence exerted by mainland Greek states (i.e. Mycenae) under the umbrella of ‘Mycenaeanization’ poses difficulties when applied to Crete (Preston, 2004). Changes in funerary, ceramic, and administrative practices appear in the LM II period at Knossos, although the presence of new mainland Greek ceramic elements in the archaeological record does not necessarily reflect a sudden shift in beliefs, political organization, or ethnic identity (Driessen & Langohr, 2007).
The collected data include ceramic vessels from both ritual and daily settlement contexts and incorporate both locally made and imported examples from pan-Cretan and off-island production centres. All non-ceramic examples, i.e. stone or metal artefacts, are excluded from this dataset. Since the rationale for the selection and publication of the data varies from one publication to another, in most instances, the published ceramics added to the database make up less than 1% of all excavated sherds. The quality, organization, and selection of the published material are also dependent on the excavation date and the priorities of the excavators. For example, although fragments of coarse cooking-ware are recovered in large quantities during excavation, they are variably included in publications as itemized catalogue entries. Consequently, there is an imbalance in the quantity of ceramics recorded in the database, ranging from 1 to 100% of the total excavated material. Therefore, aside from its significant homogeneity, WTC data also differs from the Cretan dataset through its analysis by a single ceramic expert. In cleaning this data, we first dropped artefacts of ‘Unknown’ category, even if originally their original shape type, i.e. open or closed, was known. Each ceramic entry was assigned a relative date as noted in the publication (see Table 1).
For our analysis, we further clustered relative ceramic dates into five larger temporal groups: LM II, LM IIIA1 (Final Palatial); LM IIIA2, LM IIIB1, and LM IIIB2 (Post Palatial). This was necessary as the variable study of ceramics across Crete over the last century has resulted in the identification of sub-sequences that are inconsistently identified across the island. Secondly, we excluded artefacts that did not have a confirmed single date, that is entries dated within a range, giving us a final reduced dataset of approximately 7000 entries. All the figures in this paper represent this unambiguous set. To test the robustness of our temporal classification we also considered the effect of including 400 + artefacts which ‘almost’ certainly belong to one period, e.g. LM IIIA, though with uncertainty regarding whether they belong to the first or second half of the period. What we are left with, therefore, is a highly sorted collection of ceramics produced and used during LBA Crete.
The recorded ceramics reflect a range of excavated vessels but, unlike the WTC data, are less of a representative sample of what was excavated or possibly used in antiquity. The spatial heterogeneity of the data (e.g. Chania has a disproportionate number of cups) is in total contrast to the homogeneity of the WTC ceramic distribution. Finally, although each of the five periods is represented well in the dataset with roughly 1200, 2500, 1400, 2200, and 700 artefacts respectively, there is wide disparity in individual site assemblage size. This is particularly so for the LM IIIA through LM IIIB periods for which Chania and Kommos, due to continuous occupation, provide almost all the data. These two sites benefit from having been excavated in the last 30–40 years, resulting in some of the best published archaeological sites on the island. With these discrepancies in mind, we consider that the situation is best ameliorated by spatially averaging across Crete for each temporal group, and avoiding direct site analysis when and where it is misleading.
The resulting 49 ceramic types provide us with our initial vocabulary of Cretan value-free words. We stress that a classification based on morphology alone may not be the most efficient way of projecting the artefacts from their high-dimensional space onto a manageable set of classifiers. For example, Gronenborn et al. (2017) also use decorative motifs in identifying change in Central European LBK ceramics. The present data was not collected with the goal of supporting this type of analysis, making it difficult to establish correlations. This is something that we can only determine post-hoc.
With our WTC and Cretan datasets in mind, we can now ask the following questions: within the chosen ceramic categories, how do we compare data from different archaeological assemblages and different spatio-temporal scales?
Quantifying Assemblage Change
We begin with the fundamental question: How do the WTC and LBA Cretan data vary in time? For a given period, we consider the entirety of the WTC and Cretan data obtained by aggregating the spatially separated assemblages. A key feature of the WTC data is its spatial homogeneity, which makes synchronous aggregation a simple exercise, regardless of how we do it. The Cretan dataset is more varied, consisting of several assemblages which can be aggregated and subdivided in many ways with strong spatial heterogeneity. We begin simply, by employing census aggregation to combine and count Cretan data from a given time period, across all sites. The resulting 49 ceramic categories are presented in Fig. 2.

Artifact distribution in the Cretan dataset ranked by frequency for each of the n = 49 categories (census aggregation). The inset shows the total number of entries for each site. For each artifact type, the bar is split into different colours according to a deposition site
With a way of categorising our artefacts, we can now describe an assemblage. Each artefact in our assemblage is affixed with a category label (‘word’), e.g. kylix, drawn from a list of 49 words for our Cretan ceramics, and 13 words for the WTC ceramics. We stress that the non-semantic nature of our analysis makes this a list and not a dictionary. These categories partition the assemblage so that no artefact belongs to two categories. We do not ask that each category is represented by at least one artefact in all assemblages, although the totality of the data for either the Cretan LBA or WTC will have all categories populated. Each assemblage is now no more than a word-heap of labels. The simplest way to organise the assemblage from category entries alone is to rank each word according to its frequency, ranging from the most to the least frequent. To demonstrate typical assemblage behaviour, in Fig. 2 we rank Cretan LBA ceramics for the totality of the data, i.e. the sum of all the spatial Cretan data over all periods, partitioned over our 49 word-categories. It should be noted that here we take each category as originally published, although some categories could be combined, i.e. thymatirion and burner (for changes to site specific naming conventions and their standardization in the utilized dataset, see Gheorghiade, 2020).
The Fig. 2 logarithmic plot is dominated by a relatively few categories (twelve with over 100 artefacts). This dominance of assemblages by a few artefact types or labels with an elastic tail is generic behaviour. It occurs equally for WTC assemblages, and for the Cretan LBA sub-assemblages of interest to us in which we aggregate over space for sequential time slices. To be even more parsimonious, we take a non-semantic view in which we can drop the word-labels and simply keep the profile (ranked histogram) of the assemblages with the relevant frequencies.
A hypothetical case might consider the comparison of assemblages from a given site (or aggregate of sites). Over time, a change with the adoption and integration of new ceramic traditions might be represented in the histogram profile of the assemblage by its broadening and then re-narrowing, moving from a relatively ‘pure’ state to a different ‘pure’ state via a mixed state. This replacement, known from frequency seriation diagrams, is represented as a ‘cycle’ moving an assemblage from a unified to a more diverse state, and finally a more unified state (see Diachenko & Sobkowiak-Tabaka, 2022). This does not require the words to be attached to the labels as this broadening and narrowing of the profile can be understood as an increase and subsequent decrease in the diversity of an assemblage. This is the observation that we employ here when considering diversity change as a proxy for cultural change.
Shannon Entropy and Diversity
Our starting point is Shannon information or, equivalently, Shannon entropy (Shannon, 1948) in the sense of syntactic, or rather, non-semantic information (for detailed discussion, see Sloman, 2013). In his original paper, Shannon was concerned with the ‘information’ contained in collections of symbols (‘messages’). Even as symbols (labels) Shannon’s use of information as a measure of the ‘surprisal’ induced by a set of symbols is equally valid for the present assemblage labels. In the same way that Shannon gives no meaning to the symbols, we give no meaning to the words on the labels. With these caveats, assemblages are space–time word-heaps permitting information-led word-frequency analysis. To analyse these word-heaps we repurpose tools from ecology to characterise them by their diversity (Jost, 2006). The advantage is that diversity, although related to Shannon information, has a concrete meaning when used correctly and it avoids the problems of colloquial misuse associated with ‘information’.
As anticipated, diversity is related to entropy, a measure of the unexpectedness of the assemblage. Entropy is maximized when all artefact types are equally populated in the assemblage histogram and minimised as the histogram peaks leftwards until only one final type occurs. To quantify this analysis, we attach a number i (i = 1,2,…,n), where n = 49 for each Cretan category entry. This replaces the word pile with a number pile. We can suppose that, in the histogram of Fig. 2, the number of artefacts of category i in an assemblage of N artefacts is \({x}_{i}\). The frequency of artefacts of category i in the assemblage will be \({p}_{i} = {x}_{i} /N\), resulting in the likelihood that a lucky dip for an artefact in the assemblage would produce one from this category.
The Shannon entropy \({H}_{1}\) is the average ‘surprisal’ \(\mathrm{ln}1/{p}_{i}\) associated with finding an artefact of type i (Tribus, 1961). Although Shannon entropy does not quite have the properties of diversity, it is a diversity index in that it rises and falls as diversity rises and falls. It was the behaviour of the Shannon diversity index observed in WTC pottery (Diachenko et al., 2020) with its similar emphasis on morphology that prompted the present analysis of Cretan data. Entropy itself does not satisfy the basic intuitive doubling property of diversity (Hill, 1973), namely that aggregating equally sized disjoint assemblages with identical diversities gives an assemblage with the sum of the diversities. Many purported definitions for diversity in the archaeological literature fail this simple test, which here we insist upon it for consistency.
The function of Shannon entropy which provides a diversity satisfying this additivity is its exponential (Jost, 2006). The meaning of the suffix 1 on \({D}_{1}\) will become clear later.
This numbers diversity \({D}_{1}\) lies between 1 and n and it is the effective number of artefact types in the assemblage, an attribute of an assemblage that is easily understood. However, since \({D}_{1}\) rises or falls with H we can use either measure to describe relative change. With the above in mind, we define numbers diversity as ‘Diversity’.
The diversity of the assemblage will depend on the categorization scheme. Here, we have assumed a common ‘core’ of morphological categories (including the most frequently populated). Our interest lies not in the absolute values of Diversity, but rather the direction of its change. Our assumption is that all ‘reasonable’ categorizations could identify a rise or fall in Diversity with greater or less efficiency if it were present.
Assemblage Aggregation
The assemblages of greatest interest to us are aggregations of data from all five Cretan sites, for the five selected periods. As mentioned earlier, there are two corresponding approaches to assemblages, depending on whether we think of them as censuses or as samples. For example, suppose we aggregate assemblages from two sites comprised of M and N artefacts respectively. Consider a particular artefact type (e.g. a jug, label i) and suppose that there are m jugs in the former assemblage and n jugs in the latter.
For census aggregation (C) we simply combine the assemblages. This results in \((m+n)\) jugs in a total of \((M+N)\) artefacts. The frequency of jugs, for the purpose of (Eq. (1)), is:
On the other hand, effective aggregation (E) treats each sub-assemblage as a sample from a larger ‘undiscovered’ assemblage. Statistically, this requires that all assemblages are given equal weight or status. Here, we are averaging the individual frequencies \(p = m/M\) and \(q = n/N\) for finding a jug in the two sets. The effective ‘jug’ frequency to be inserted in (Eq. 1) is now:
This generalises directly to more assemblages. The frequencies \({p}_{i}\) for the observed (census) assemblages are termed as naive or plug-in estimators in the literature (e.g. Ricci et al., 2021).
There is a potential problem here in that our deposition site assemblages are aggregates of smaller assemblages and which, due to lack of knowledge, we must interpret as census aggregates. In this we trust to practicality as to when to take an assemblage as effective, bundled together from sub-assemblages treated as censuses. For the Cretan data, we do not look at levels below the five deposition site assemblages for each period, although for the granularity of the WTC data see Diachenko et al. (2020). Since this dataset represents only a small percentage of all excavated material, these assemblages can also be regarded as effective (E). This poses problems for smaller assemblages, that are not the result of excavation bias, but rather historical reality. For example, the absence of all but small quantities of data resulting from the abandonment of a site, which is indeed the case for some Cretan sites during the LBA.
Provisional Results
Figure 3 displays the Shannon Diversity for the WTC Tripolye ceramics and Cretan ceramics aggregated across all sites as a function of time over their relative time periods for the plug-in estimators. The Diversity that follows from the spatial aggregation over all sites at a given time is identified as γ- Diversity. In each case, we take both census (C) and effective (E) aggregation of the five deposition site assemblages for each period.

a The change in Shannon γ-Diversity (not Shannon entropy) of WTC pottery morphology from 4100 to 3600 BCE (where data permits). a lacks reliable data for time units 2 and 3. The dotted line is used purely as a guide. b The change in Shannon γ-Diversity for Cretan ceramic morphology spanning LM II to LM IIIB2. The two Cretan graphs correspond to different aggregation protocols
Census and effective aggregation coincide for the WTC data because of the extreme homogeneity of the synchronous sub-assemblages, and because all aggregated assemblages are large. The resulting single graph (Fig. 3a) highlights the halving of diversity from its peak. We note that the act of consistently removing bowls from our listed categories will reduce the absolute Diversity but have no effect on whether it rises and falls (for reproducibility, see Gheorghiade & Vasiliauskaite, 2023).
The Cretan data shown in Fig. 3b takes site assemblages aggregated period by period. Ignoring statistical fluctuations, we can identify a drop in diversity from the peak for effective aggregation, but less reliably for census aggregation. According to the aggregation method, the somewhat different outcomes for later time periods reflect the dominance of Chania and Kommos for LM IIIB data. Large or small, they are skewed by the accidents of excavation and selection to have low Diversity. For example, some sites excavated in the early twentieth century will not have the same robust datasets. Most artefacts from this period would not have been aggregated and published quantitatively using the same amount of detail used today. Giving the small sites equal weight in effective aggregation lowers the overall diversity.
When Is an Assemblage Large Enough?
Figures 3a and 3b did not take statistical fluctuations into account, leading to the question how large does an assemblage need to be for the effects of a small size to be rendered unimportant? (e.g. see Wolda, 1981). One of the most obvious sources of uncertainty in the Diversity of sample data is bias. For example, extending the assemblage data via future excavation can only increase Diversity, therefore systematically underestimating Diversity. For cases where the different categories are randomly and independently accessed (multinomial) the underestimate is, proportionately, the Miller-Madow (Miller & Madow, 1954) correction factor \((n-1)/2N\) for an assemblage of size N with n categories (Ricci et al., 2021). For the WTC data, with a limited number of categories and a large dataset, the correction is small. The Cretan data have a much larger category count n and smaller assemblages which are not multinomial. Nonetheless, if we take this correction factor as a plausible rough estimate of bias, then with Cretan-wide aggregates of roughly 1200, 2500, 1400, 2200, 700 artifacts for each of the five periods, then we estimate that bias changes the results of Fig. 3 by only a few percent. The skewed nature of the data suggests larger errors that are potentially still manageable, but a focus on smaller, individual sites and time periods returns poorer results. The five Cretan sites and five temporal-periods result in 22 assemblages, and their Diversities are shown in Fig. 4.

The observed Shannon Diversity (\(q=1\)) against assemblage size for 22 Cretan sub-assemblages with data
Figure 4 suggests that we can only really ignore small size effects when assemblage size exceeds 100 artefacts (commensurate with the Miller-Madow correction factor). With 49 categories, it seems plausible that there will be size effects until the set is large enough for most categories to have the opportunity to be sampled. Individual sites (excepting Kommos) show a logarithmic increase in Diversity with size. The conclusion is that although we are relatively comfortable with Cretan-wide aggregation, local assemblages must be treated with care.
Generalised Diversities and q-Number
With all these caveats, the changes for census diversity signalled in Fig. 3b are not very strong. One possible way forward is to generalise Diversity to preferentially weigh either the head or the tail in the Fig. 2 distribution. For example, the tail highlights several categories with only one artefact. With further discovery and excavation, this might very well be extended through the creation of additional categories. It is possible that the recombination of listed categories, i.e. scoop with ladle or bucket with basin, would remove some of the outliers in this figure. On the other hand, the most dominant categories in Fig. 2, primarily cups, are inclined to swamp the picture. With Shannon Diversity each artefact is weighted equally, making only a small contribution. This front-loaded domination and ambiguous tail in the data can be circumvented by generalising the mathematical definition of Diversity with the guiding rule that the diversities of disjoint assemblages (of equal diversity and equal size) add up when the sets are joined. This leads to a unique family of diversities derived from generalised entropy, labelled by q > 0 (Jost, 2006):
In ecology q is the Hill index (Hill, 1973), while in mathematics the order. Still defined as the effective number of categories present in the assemblage, \({D}_{q}\left(X\right)\) takes values between 1 and n, where n is the total number of categories (49 for Crete). By taking the limit of q to 1 we return to Shannon Diversity (hence the suffix on D in Eq. (1)). Other familiar diversities are Richness (\(q=0\)) and Gini-Simpson I Diversity (\(q=2\)). By definition (and intuitively) \({D}_{q}\left(X\right)\) increases with decreasing q, as the less frequently populated artefact types are given more status. In supporting the singling out of categories of artefacts that occur rarely or frequently, they showcase change differently.
There are different routes to achieving (Eq. (2)), according to how entropy is generalised. For example, the family of entropies \({R}_{q}\), after Renyi (1970), labelled by the order \(q\ge 0\), uniquely generalises Shannon’s entropy. Entropy has its own additivity rule, that the total number of questions required to determine truly independent attributes is the sum of the questions needed for each attribute individually. Only Renyi entropies permit this, although there are many entropy-like entities that have been proposed which fail in this regard. The most familiar of these is the Tsallis-Havrda-Charvat entropy \({T}_{q}\), known as Tsallis entropy (Havrda & Charvat, 1967; Tsallis, 2009), again labelled by an index \(q\ge 0\). Tsallis entropy (\(q=2\)) is known as the Gini-Simpson ‘impurity’, which we cannot simply interpret as ‘information’ (e.g. see Pressé et al., 2013). However, both the Renyi and Tsallis entropies lead to the identical generalised Diversity \({D}_{q}\) of (Eq. (2)) (Jost, 2006).
Considering Variance and Bias
In addition to bias, there is a question of variance in the fluctuations around the mean. It could be argued that there are no statistical errors for censuses, since a census is based on observable data, and we can persist with plugin estimators. In practice, this is not quite the case. As mentioned, census assemblages result from the combination of assemblages into a single table. For effective assemblages, an appropriate extrapolation of the assemblage (maintaining frequencies) is conducted before combination. Either way, both result in a joint assemblage which, in each case, can be considered as having some associated statistical uncertainty, allowing for comparisons.
An estimate of this for Shannon Diversity gives an upper bound (fractionally) of \(\mathrm{ln}(n)/2\sqrt{N}\) for an assemblage of size N with n categories (Ricci et al., 2021). For a Cretan aggregation of 1000 artefacts this would correspond to a maximum, but manageable, variance of less than one unit for a typical Diversity of 15. Again, this assumes a multinomial distribution, which is unrealistic, but we can use this to give rough estimates of uncertainty. We expect smaller fluctuations for \(q=2\) and larger for \(q=1/2\). As a simple guess for our data, for each case we have attempted a simple exercise in robustness by replacing approximately 10% of the artefacts in the assemblages. That is, we replaced (the smallest integer greater than) 10% of the artefacts randomly. For \(q=1\) fluctuations are typically a unit or less. There is a delicate balance to be drawn, in that the tail is the least statistically robust part of the data. For that reason, we give less credence to \(q=0\) richness, where \({D}_{0}\) is the number of non-empty categories. There are more sophisticated ways for estimating missing categories (e.g. Chao et al., 2014; Colwell & Chao, 2022; Willis, 2019; Seweryn et al., 2020) but our dataset is too irregular for such estimates to be useful here (e.g. no doublets in Fig. 2). We have kept the \(q=0\) graph because of the intuitive nature of richness. For the WTC data of Fig. 3a, there was no need to look at lower q values since the rise and fall of the diversity is strong. For individual site assemblages in given time periods (Fig. 4), an assemblage of 100 would give a threefold increase in fractional variance but, since variances are halved, the overall effect is still of the order of one unit.
Henceforth, all calculations are based on Eq. (1) and Eq. (2) (see Gheorghiade & Vasiliauskaite, 2023). For census aggregation, we restrict ourselves to \(0 \le q \le 2\). This restriction is due to constraints on the convexity of entropy (Jost, 2007), with the Diversity \({D}_{q}\) for \(q=2\) now equalling the inverse of Simpson’s C-Measure. This incorporates a subtlety (see Jost, 2006), where sites are weighted according to the qth power of their size.
Applications and Results
With these caveats the standard error bars of Fig. 5 show that the variability in the observed results for γ-Diversity is small, in contrast to absolute values of diversity. Figure 5 shows the γ-Diversity, with Fig. 5a highlighting census (C) aggregation and 5b effective (E) aggregation for q = 0, ½, 1 and 2.

The γ-Diversity for Crete for LM II–LM IIIB2 for different q-values with census (a) and effective (b) aggregation shown with open symbols and solid lines. To illustrate the possible uncertainty for each data point, the figure also shows the results for randomised data sets using closed symbols and dashed lines. These artificial datasets are obtained by sampling with replacements from the data used for each set of parameters and repeating the procedure 100 times (known as bootstrapping). The mean and standard deviation obtained from the artificial data are linked by dashed lines. Note that the scale is compressed in comparison to Fig. 3b. For \(q=0\) census and effective aggregation are identical
The noise added to the data points in Fig. 5 represents, in part, the uncertainty in the data due to ambiguous classification. Our assumption—that ambiguous data might be randomly distributed in category—is not quite the case for the Cretan data. There is a small dataset (400 +) of artefacts of slightly indeterminate date (e.g. generally dated to LM IIIA) not included in Fig. 3b, and we have examined the effects of distributing them between permissible periods. Since adding artefacts to assemblages increases their diversity, the effect in this case with fixed endpoints is always to make any rise and fall of the effective assemblages more pronounced. To achieve the maximum effect, we allocated the ambiguous LM IIIA data just to LM IIIA1 and the ambiguous LM IIIB data just to LM IIIB1 (an approximate 10% increase in assemblage size). For \(q=1\) the effect at LM IIIA1 and LM IIIB1 is to increase diversity at LM IIIA1 and LM IIIB1 by about two units for both types of aggregation. These are somewhat larger effects than those seen in Fig. 5 and reflect the non-random nature of the omitted data. Achieving a more equitable distribution of ambiguous data, beyond trial and error, would likely have a smaller effect. Graphs showing the effect of incorporating these ambiguously dated artefacts are given in Gheorghiade & Vasiliauskaite, 2023.
Our results in Fig. 5 show there is a trade-off between Diversity and aggregation method. For example, for q = 0 both aggregation methods coincide, but the statistical errors are greater. Since our interest here lies in change in Diversity the intentional exclusion of certain data types (e.g. coarse kitchenware) makes no reference to the amount of such data. As there always is such data, changes in the Richness (\(q=0\) Diversity) of the data will largely be unaffected. At the other extreme, for \(q=2\)(Gini-Simpson or Simpson-C) the situation is different. With emphasis on heavily populated datatypes, data on extremely common types needs to be uniformly accurate as it will be important. Nonetheless, considering the lack of change in Diversity for \(q=2\) in Fig. 5 empirically this is not a problem.
Given these qualifications, all of which enhance the central region, it can be argued that, for effective aggregation, Cretan γ-Diversity shows a moderate rise and fall across the entire period for Shannon’s \(q=1\) (see Fig. 3b for the expanded graph) but is essentially unchanged for Gini-Simpson’s (\(q=2\)) diversity. Finally, at \(q = 0\), with more emphasis on the longer part of the tail, we do see a genuine rise and fall in diversity over the period driven by some of the less dominant categories. A similar but less strong effect is also seen for \(q ={~}^{1}\!\left/ \!{~}_{2}\right.\) with its emphasis on the tail. For the error-prone q = 0 the two methods coincide, highlighting an even stronger effect. Census aggregation exhibits a weaker pattern, only beginning to show a rise and fall in diversity of the type associated with a cultural shift for \(q={~}^{1}\!\left/ \!{~}_{2}\right.\) and less. For the much larger Southwest Social Networks (SWSN) Project dataset, Simpson’s C-measure of \(q=2\) was sufficient (Hegmon et al., 2016). As we have seen above, this is too blunt of a tool for the present data.
Assessing Heterogeneity
In interpreting Fig. 5 further, we see that synchronous WTC data across the plain is spatially very homogeneous whereas LBA Cretan data around the island is not. In fact, information on the heterogeneity of the sites is built into the diversity formalism. Aggregating assemblages implies information loss since one must ask questions before the individual assemblages can be reconstituted.
This ‘lost’ information reappears as information about the heterogeneity of sites (their β-Diversity).
β and \(\alpha\) Diversities
For Shannon entropy, for which information has a clear meaning, the loss of information on aggregation (Jost, 2006) can be understood as:
where the α-entropy H1α is the average of all assemblage entropies from all five sites weighted (C) or not (E). This is guaranteed to be smaller than the entropy of the aggregated assemblages (less questions needed). However, we have argued that it is better to work with diversity where the equivalent decomposition of the γ-Diversity relation is:
The β-Diversity of the assemblage, its heterogeneity, is understood as the effective number of sites that constitute the aggregated assemblage. It takes values between 1 (in the case of maximal homogeneity when assemblages are indistinguishable) and the number of deposition sites (when their assemblages are maximally heterogeneous and bear no statistical similarity). As before, our assemblages consist of sets of samples from sites in each period. For Crete, we calculated β-Diversity across the sites in each period, for which \({1\le D}_{1}^{\beta }\le 5\) for the first three periods (LM II, LM IIIA1 and LM IIIA2). For LM IIIB1 we have \({1\le D}_{1}^{\beta }\le 4\) and \({1\le D}_{1}^{\beta }\le 3\) for LM IIIB2, as we do not have any data from Palaikastro for the former, and from Mochlos for the latter period.
For the first three time periods, we find that with the β-Diversity around 1.5 (\({D}_{1}^{\beta }\approx 1.5\)), by either aggregation method, indicates a surprising homogeneity. This measure suggests that a lack of diversity in the five sites meaning that they behave as we might expect if only one or two sites had distinctive assemblages. For the LM IIIB1 and LM IIIB2 periods, we find that \({D}_{1}^{\beta }\approx 1\) (C) and 2 (E). These are at the bounds of our expectations since only Kommos and Chania contribute any significant LM IIIB1 and LM IIIB2 material.
For generalised diversity (Jost, 2006) the γ-Diversity for the aggregated Cretan assemblage factorises in a similar manner:
Note that \(\alpha\)-diversity represents a modified geometric mean of the individual diversities. Jost (2006) further elaborates on the technical details which are omitted here but included in our GitHub repository (see Gheorghiade & Vasiliauskaite, 2023).
Extending the analysis from Shannon \(q=1\) to \(q={~}^{1}\!\left/ \!{~}_{2}\right.\) and \(2\) the outcome is that, at later time periods, we continue to have a bifurcation according to the aggregation, with \({D}_{q}^{\beta }\approx 2\) (E) and \({D}_{q}^{\beta }\approx 1\) (C) for all q values. At earlier times, for \(q={~}^{1}\!\left/ \!{~}_{2}\right.\) the \(\beta\)-Diversity of the five Cretan sites increases to a value closer to \({D}_{1/2}^{\beta }\approx 2\); for \(q=2\) it lowers to \({D}_{2}^{\beta }\approx 1\) for both census and effective aggregation.
This almost total homogeneity for census aggregation looks puzzling, since assemblages from different sites are often very different in their composition. Although not a complete explanation, this can be attributed to the nature of diversity as non-semantic, not acknowledging or reading category labels. Interestingly, such behaviour is a familiar outcome in several other contexts (e.g. see Zaneveld et al., 2017) where it is known as the ‘Anna Karenina Principle’ (AKP), from the opening line of Tolstoy’s Anna Karenina: ‘Happy families are all alike; every unhappy family is unhappy in its own way’. In this case, diverse site-periods are alike, but as they become less diverse, each one of them does it in their own way.
Similarity Indices
To unpick this failure of seeming homogeneity, we can identify similarities between synchronous sites on a local (pairwise) basis from the \(\beta\)-Diversity. For example, consider two assemblages A and B, which can be used to construct the \(\beta\)-Diversity \({D}_{q}^{\beta }(A,B)\) in the usual way. It is more intuitive to rewrite \({D}_{q}^{\beta }(A,B)\) in terms of the pairwise similarity (Jost, 2006) \({S}_{q}(A,B)\) as:
We have \({S}_{q}\left(A, B\right)=1\) when the assemblages from both sites are identical and \({D}_{\beta }^{q}\left(A,B\right)\) is 1. On the other hand, when we have no similarity between these assemblages \({D}_{\beta }^{q}\left(A,B\right)=2\) (i.e. the maximal \(\beta\)-Diversity value in cases where the assemblage consists of two ceramic sets—sites) then \({S}_{q}\left(A, B\right)=0.\) For \({S}_{q}\left(A, B\right)=0.5\) we find the effective number of “sites” is between one and two, \({D}_{\beta }^{q}\left(A,B\right)=4/3\). With all its caveats, effective aggregation (E) seems to be the more familiar way to proceed.
We note that when \(q=0\), \({S}_{q}\left(A,B\right)\) is the familiar Jaccard similarity index, which emphasizes the infrequent artefact types at the tail end of Fig. 2. For \(q=2\), \({S}_{2}\left(A,B\right)\), the Morisita-Horn index shows indifference to infrequent artefact types (Courmier et al., 2018; Habiba et al., 2018). Other values of q do not give familiar indices. Individual site-on-site similarity between synchronous assemblages (for each period) is varied due to the limited heterogeneous data, resulting in unhelpful results. Instead, we opt to take the average similarity of each site, and each period, with its four neighbours. Figure 6 visualizes the results for two extremes: \(q=2\) Morisita-Horn and \(q=0\) Jaccard indices. These figures exclude error bars (smaller for Morisita-Horn), as the goal is to seek out general trends.

The averaged similarity for any given site with its four neighbours for each period for a \(q=2\) Morisita-Horn and b \(q=0\) Jaccard similarity indices. Zero similarity denotes no data
As with Gronenborn et al. (2017) and Diachenko and Sobkowiak-Tabaka (2022), ancillary contextual data are required to make sense of these results. We consider a similarity of 0.5 as signalling the average independence/indifference of a site with or to its neighbours. For \(q=2\) (Fig. 6a), we see a strong similarity between each site and its neighbours for the LM II, LM IIIA periods, and a dissimilarity between sites by LM IIIB1. This of course makes sense since we only have two sites with substantial LM IIIB material—Chania and Kommos—with the overall quantity of data decreasing for these periods at all other sites. Moreover, within these sites, the distinction between LM IIIB1 and LM IIIB2 ceramics is not always clear, with the highest resolution in this regard visible only at Chania. Nonetheless, the emphasis here is on common artefacts. For Jaccard similarity of Fig. 6b with its emphasis on artefact types, the result is a common mild dissimilarity between sites and their neighbours (except for Mochlos where the dissimilarity is stronger) for the LM III, LM IIIA periods and almost total dissimilarity thereafter. This makes sense, of course, since we have less data from Mochlos dated to LM II and LM IIIB. The results for \(q=1\) (Shannon) with its equal weightings are essentially intermediate between these, giving support to the often-unreliable Jaccard results since we can make no realistic missing-data analysis. One way to understand the drop in similarities is by assuming that individual sites are adopting or bringing over new styles in the less common categories (thereby increasing Cretan Diversity), but in different ways on a site-by-site basis and therefore decreasing similarity. Caution is needed in that averaging can hide useful information. For example, if we look at Knossos in Figs. 6a and 6b, we see no sign of the decay in diversity that was present in Fig. 4. Graphs incorporating the ambiguously dated artefacts can be found in Gheorghiade & Vasiliauskaite, 2023, although they do not change the overall picture.
For the WTC data of Fig. 3a, it was suggested (Diachenko et al., 2020) that the details in Fig. 3a encode smaller diversity cycles that can be associated with immigration of other WTC groups from the west. To see if, despite Cretan-wide relative temporal homogeneity, there is any internal temporal structure to the Cretan data of Fig. 5 we have also looked at the similarity \({S}_{q}\) between time-site data at consecutive time periods as derived from pairwise \(\beta\)-Diversity. Specifically, for Table 1, we computed a pairwise similarity between each pair of sites where one site comes from one period and the other from a consecutive period, averaging over all possible pairs to obtain a global estimate of the similarity of two periods (thereby helping to keep errors down). We assume that a site which is empty at a particular period is maximally dissimilar (\({S}_{q}=0\)) to other sites and this is accounted for in the average. For that reason, LM IIIB2 will differ from LM IIIB1 because of its limited data.
As Fig. 7 shows, with effective aggregation there is a common picture across all q values; namely that LM II, LM IIIA1, and LM IIIA2 are equally similar but, as with synchronous similarities, LM IIIA2 differs significantly from LM IIIB1. The larger the q value, the greater the similarity between the first three periods; the smaller the q, the less similarity can be observed. Further, as we anticipated, LM IIIB2 differs greatly from LM IIIB1, which is less reliable due to the limited data from this period. For example, only two sites—Chania and Kommos—provide substantial data from LM IIIB1 and LM IIIB2, with material from Chania dominating the assemblage. We now understand the peaks in the diversity profiles in Fig. 5b as characterising the transition between LM IIIA1 and LM IIIB1 represented by assemblages with different compositions before and after for which, more types are present.

Pairwise (effective) averaged similarity of all possible pairs of sites in two consecutive periods for four values of q where \(q=0\) is averaged Jaccard similarity and \(q=2\) averaged Morisita-Horn similarity
Numbers are important. Again, taking a similarity of 0.5 as signalling the independence/indifference of the two assemblages to each other, for \(q=2\) we see a strong similarity between the LM II, LM IIIA periods and indifference by LM IIIB1. The \(q=2\) Morosita-Horn ignores less-populated categories. As we move towards \(q=0\) (Jaccard) which just counts the categories present, LM II, and LM IIIA become mutually independent, but all strongly dissimilar to LM IIIB1. This is a consequence of the strong heterogeneity of the LBA Cretan sites, in stark contrast to WTC ceramics, whose spatial homogeneity is so striking.
Summary and Discussion
We suggested earlier that patterns represented by the rise and fall in diversity should trigger an examination of the data to see if social transformations are reflected (reflective cycles) (Gronenborn et al., 2017) or not (self-organized cycles). In the case of cultural cycles, the rise-and-fall diversity patterns represent the replacement of one cultural trait by another. For example, the presence of a new trait which occurs in relatively low proportions which grows as the dominating trait declines proportionally. From a diversity viewpoint, this replacement (known from its frequency seriation diagrams) is represented by a cycle moving an assemblage from a more unified state to more diverse state, and back again (Diachenko & Sobkowiak-Tabaka, 2022).
This is exemplified by the WTC ceramics from the Southern Bug and Dnieper interfluve. The rise and fall in their diversity (Fig. 3a) are shown by an increasing number of vessel types (from 8 in time unit 1, to 9–11 in time units 4–9) and their subsequent decrease (to 6 in time unit 10). Unpacking the data, this, in large part, reflects the replacement of sphero-conical vessels and craters by biconical and crater-shaped vessels. Upon this overall nearly sigmoid-shaped profile, local deviations in diversity in time units 4, 6, and 9 correspond to the immigration of population groups from the west to the Southern Bug and Dnieper interfluve (Diachenko & Sobkowiak-Tabaka, 2022; Diachenko et al., 2020).
The homogeneity of the WTC assemblages suggests the intensive interaction between populations at different sites. This is supported by the relatively synchronous (span of c. 50-years) change in pottery shapes across different settlements and the roughly similar (with a few percent deviation) quantitative distribution of these shapes in different houses. These changes can be treated akin to modern day fashion cycles. The latter statement finds its conformation in the distribution of WTC vessel shapes beyond the analysed region (e.g. Markevich, 1981; Ryzhov, 2021).
The LBA Cretan data has some similarities with WTC data when only ceramics are taken as a proxy, with an island-wide rise and fall in diversity of greater or lesser extent (Fig. 5) according to our emphasis on less frequent ceramic types. We keep in mind that any patterns we observe are likely to reflect our collected dataset as much as true cultural change (Murray, 2021). There is a major difference in that the heterogeneity of Cretan coastal sites is reflected in part in the heterogeneity of the assemblages which impedes statistical robustness and complicates our understanding of aggregation and its realisation. Nonetheless, by whatever means we aggregate, we do see a change over this 250-year period. Despite the introduction of new shapes and vessels in LM II at Knossos, it seems that this change across the rest of the island was slow and spanned multiple periods. This suggests that the adoption of new vessel shapes and styles, such as the kylix, did not occur suddenly, even though archaeologically it appears as such in the record.
In more detail, the dispersal of the data points in Fig. 4 reflects the heterogeneity of the sites within the general envelope of individual sites largely showing a moderate rise and fall (or maintenance) of diversity over time. Take Kommos, for example. It shows consistently high diversity over all time periods until LM IIIB2 when it almost disappears from our records (the final low-lying isolated star). We attribute this in large part to it being the important port site in southern Crete with the diversity of the imports being reflected in the recorded vessels. Knossos, however, considered at the end of LM II to have a key role, looks to provide a counterexample, showing a continual fall in diversity across the studied period from the unexpectedly low level of \({D}_{1} = 10\) to effectively zero. This, in part, is a limitation of our dataset providing less quantifiable ceramic material from one of the most important sites on Crete, the palace of Knossos, which was excavated in the early 1900’s (Popham, 1970, 1984; with relevant data from Evans, 1906; Hatzaki, 2005; Mountjoy et al., 2003; for the complete bibliography, see Gheorghiade & Vasiliauskaite, 2023). Here the focus was less on quantification and more on providing an overview of the building and ceramic typology of the period. Gold, silver, and exotic material objects were also not part of this ceramic dataset, although they occur at Knossos and at other sites across the island especially in funerary contexts. We would expect a much higher diversity in the overall material culture at each of these sites both during the period under analysis and earlier. Presently, this is obscured by the exclusion of these materials from the dataset.
Oddly, in early periods, this dissimilarity is not present in our data (Fig. 6). We can read this in several ways. It is possible that the similarities observed in the LM II–LM IIIA2 data (Figs. 6 and Table 1) reflect the slow adoption of a new, mainland inspired ceramic repertoire on a site-by-site basis. We might argue that these similarities are the result of cultural transmission. For well-populated typologies, their common trajectories were presumably grounded in intensive interaction, with vessel shapes and styles incorporated by settlements to various degrees based on specific wants and needs. Imports could have been transported either through trade or the movement of people across the island. The incorporation of these new shapes and categories over time leads to the similarity which we see in our data. Whether this was spurred by Knossos as the sole palatial centre extending its influence across the island is not something we can address by simply comparing the diversity and similarity in our dataset; however, we start off in LM II with slight variations in both, suggesting that the similarity we see culminating in LM IIIA2 (Fig. 6) was the result of a long process for all sites involved, with some resisting the complete assimilation of a new ceramic repertoire. For example, the most common drinking vessel across the island, the kylix, does not appear at Palaikastro at all, suggesting that cultural change is not sudden and uniform across space and time (Porčić, 2023). As both a geographical and cultural outlier, Palaikastro keeps its somewhat lower diversity by not connecting to other sites and not adopting their styles, preferring instead to maintain its local individuality.
By contrast, in LM IIIB, we have a sharp increase in dissimilarity. This can be attributed to stark changes across the island, one of which is the discontinuation of occupation at Mochlos, Palaikastro, and Knossos. Some sites are abandoned, downsized, or relocated. Consequently, it is the ceramic evidence that becomes sparser, not so much a complete abandonment of occupation in the area. Chania in this period sees an increase in Italian shaped vessels made locally—such as the olla and scodella—and integrated into the local assemblage. Unsurprisingly, these appear as stark outliers in Fig. 2, located at the end tail of the logarithmic plot since these are unique at Chania in this late period. At Kommos, we continue to see Sardinian imports but also the production of a new, local shape, the short-neck amphora (SNA) (Rutter, 2000). We might be tempted to attribute this rise in dissimilarity to the final destruction at Knossos in LM IIIA2, resulting in a decentralization that we can see reflected in the archaeological record. While we can observe changes in the ceramic data of the period, our conclusions ought to include data from more than two sites. Presently, the data from these two very well excavated and recently published sites, while excellent for the cursory exploration presented in this paper, are themselves limiting and not sufficient for drawing broad sweeping conclusions on changes in the socio-political organization of LBA Crete. It is possible that with the addition of data from other sites, and the integration of non-ceramic evidence, our picture of similarity and diversity might change.
We cannot escape the poorly representative nature of the data with its wide variety of time-site assemblages. We saw this problem in the way that ambiguous temporal dating can lead to spurious enhancement of Diversity. This weakens the strength of our conclusions, issues to which we return in the concluding section.
Conclusions
To be is to be the value of a bound variable – Quine (1980)
This methods-oriented paper focused on applying and exploring the diversity and similarity of assemblages from two, relatively large and distinct prehistoric ceramic datasets. Despite their size, ranging from 13,700 (LBA Cretan data) to 25,000 (WTC data) entries, these datasets are best conceptualized as ‘large datasets’, rather than the ‘big data’ produced by social media conglomerates. Our goal was to apply a range of diversity measures and similarity indices to our LBA data, aimed at exploring and examining their fit and robustness. We aimed to develop a toolkit for quantifying similar archaeological data and explore the premise that diachronic change and spatial difference in assemblage composition can reflect changes and differences in cultural processes. Whenever possible, we employed a concise, and non-narrative approach guided by the principle of parsimony.
This study was motivated by earlier work on WTC Tripolye ceramics by Diachenko et al. (2020), which demonstrated the power of morphological analysis for assemblages using entropy change. This complemented earlier work by Gronenborn et al. (2017), whose analysis of the decorative entropy of LBK pottery reinforced the idea of adaptive cycles. Most of the data analysed here, however, concerned LBA Cretan data (Gheorghiade, 2020). The specific nature of WTC culture, with its house-burning, mega-sites and agglomerating populations minimizing distance of contact, led to a dataset homogeneous in space for a spatially homogeneous geography that we could not parallel for quality. By contrast, the Cretan data shows strong spatial heterogeneity, both in the geography of the coastal sites (see Fig. 1) and in their archaeological deposits. Further, the variation in size of the local assemblages and the irregular curation of the Cretan data make it less representative than the WTC data. As a result, we wrestled to obtain robust results from which to draw robust conclusions, necessitating a greater variety of tactics than was needed for the WTC data.
We accept that our act of reducing artefacts to their labels, the starting point of our analysis, is an extreme Quinean reductionism to which the familiar criticisms can be made. We are not so dismissive, depending on the questions that we ask. For example, if in a hospital we look at change in the composition of illness in hospitalised patients, we need very little from patients’ (anonymised) records to see the spread of an epidemic. We are not exactly looking for cultural epidemics here, but we can find parallels. However, to make progress, supplementary contextual data must be considered and included.
What we can say with confidence is that based on the current archaeological dataset, the applied diversity and similarity measures highlight temporal changes in the makeup of our assemblage. These changes do seem to correspond with important socio-cultural shifts during the LBA, but we caution against drawing general conclusions from our analysis in support of these hypotheses. Rather, we would argue that our analysis was successful in highlighting patterns in the collected dataset, demonstrating the use of such measures for large archaeological data. We might consider our results important for correlating diversity to change since this can signal the end of sites (by displacement). This might fit well with the observation that towards the end of the LBA on Crete, we seem to have a movement of people away from the coast and towards inland settlements. This shows the limitation of our modelling and the need, as expected, to bring in additional detailed information from other sites in the region.
The literature provides a plethora of ways in which we can attach numerical values to artefacts and their assemblages as a precursor for identifying change, both more and less sensible. As with the WTC and LBA data, we have chosen ‘information’ as the guide to enable us to remain consistent and a natural way to describe the contents of the ‘label-heaps’ that we chose to replace our archaeological assemblages. Within this framework entropy becomes the natural source of information although, colloquially, it is not ‘Jane Austen’s conception of information’ (Sloman, 2013). To avoid ambiguity in even this restricted definition of information, we have argued that we should look for changes in diversity, the effective number of artefact types in an assemblage, rather than entropy, as a better signifier of social activity. The resulting diversity from the aggregation of two disjoint sets of the same size and identical diversities, results in a diversity that is the sum of the two (Jost, 2006, 2007) This leads to a unique family of diversities derived from generalised entropy, labelled by q, the Hill number in ecology. The most familiar are Shannon Diversity (\(\mathrm{q}=1\)), Richness (\(\mathrm{q}=0\)) and (\(\mathrm{q}=2\)) Gini-Simpson Diversity or, its inverse, Simpson’s C-measure. These various diversities support the singling out of categories of artefacts that occur rarely or frequently, showcasing change differently. Consequently, in this paper, we borrowed heavily from ecological literature, where such quantitative comparisons of assemblages (e.g. plant, wildlife, insect assemblages) are routine. Non-semantic non-stories have the power to unearth endogenous and exogenous habitat change.
In a similar framework, we have looked for changes in data patterns represented by the rise and fall in Cretan diversity (unification – diversity – unification) to reflect the increasing significance of mainland Greek style artefacts. There is an issue in that, whereas ecologists have their standard classification schemes, we do not. Our hope that any reasonable classification scheme would give the same qualitative behaviour may well be true, but it is possible that different schemes amplify or suppress the effects. Labelling is an ambiguous exercise, condensing the most ‘significant’ traits an artefact possesses from a high-dimensional artefact ‘trait space’ into a lower one, in our case one essentially of display-case labels. It is important to consider the level of our ‘labels’ in archaeological taxonomies, due to the loss of information occurring with increasing levels of taxonomic hierarchy. Inevitably, we lose information on highly variable (and diverse) vessel attributes reflected at the taxonomic levels of sub-types, sub-sub-types, variants etc. We can try to minimize this loss by identifying the most informative traits to create a (decision) ‘tree’ of optimal level, behaving a little like German Komposita. We anticipate that they would be significantly smaller than the archaeological categories utilized in cataloguing artefacts. This and related approaches are currently underway. Until they have been solved, we retain the 49 archaeologically assigned labels from Fig. 1, although this number is inconveniently large for the poor statistics of smaller assemblages. Relying on changes in Diversity, rather than absolute values, provides a better handle for missing and excluded data.
A secondary concern was that of assemblage aggregation. For the Cretan assemblage, we were particularly interested in how the material changed during the LBA (LM II through LM IIIB2). This required the aggregation of data from each site, and each period. Data aggregation could proceed in two ways, according to whether we interpreted an assemblage as a census (the observed assemblage) or as a sample from a larger assemblage (the effective assemblage). Each of these approaches gave different outcomes, and we tried both, looking for a certain robustness. For Cretan-wide data (its γ- Diversity), we found the same rise and fall in Diversity shown in the WTC data (see Fig. 5), with some caveats. For heterogeneous Crete, this is only part of the story. Aggregation leads to information loss, including considerations of assemblage heterogeneity. These can be re-captured through \(\beta\)-Diversity measures, converted into more familiar similarities, e.g. Jaccard for \(q=0\); Morisita-Horn for \(q=2\). This reinforces the transitional behaviour from LM IIIA to LM IIIB that seen in Cretan γ-Diversity. These outcomes are reassuring, rather than convincing.
For all the issues with data, our broad-brush approach has not failed in an obvious way, but rather, despite data ambiguities, it has not done enough. Reflective vs. self-organized cycles cannot be distinguished by simply examining the rise-and-fall in diversity measures represented in graphs. Entropy alone falls short of ‘translation’, which has a semantic component. For example, Gronenborn et al., (2020; see also 2014, 2017, 2018) also consider secondary decoration motifs as additional components, important for the self-manifestation of social groups. Other label entries such as provenance and fabrication can also be construed as semantic insofar as they impart some sense of ‘agency’ to the assemblage composition, but given the poverty of the present Cretan data, the question about the nature of the cycle remains open.
Data Availability
Data are from primary sources as cited in text and, where possible, copies are provided as Gheorghiade and Vasiliauskaite (2023).
Code Availability
Available as Gheorghiade and Vasiliauskaite (2023).
References
Barjamovic, G., Chaney, T., Coşar, K., & Hortaçsu, A. (2019). Trade, merchants and lost cities of the Bronze Age. The Quarterly Journal of Economics, 134(3), 1455–1503. https://doi.org/10.1093/qje/qjz009
Bevan, A., Crema, E., Li, X., & Palmisano, A. (2013). Intensities, interactions and uncertainties: Some new approaches to archaeological distributions. In A. Bevan & M. Lake (Eds.), Computational approaches to archaeological space (pp. 27–52). Left Coast Press.
Chao, A., Chiu, C. H., & Hsieh, T. C. (2012). Proposing a resolution to debates on diversity partitioning. Ecology, 93, 2037–2051.
Chao, A., Gotelli, N. J., Hsieh, T. C., Sander, E. L., Ma, K. H., Colwell, R. K., & Ellison, A. M. (2014). Rarefaction and extrapolation with Hill numbers: A framework for sampling and estimation in species diversity studies. Ecological Monographs, 84, 45–67. https://doi.org/10.1890/13-0133.1
Chao, A., & Chiu, C. H. (2016). Species richness: Estimation and comparison. Wiley StatsRef: Statistics Reference Online, 1–26. https://doi.org/10.1002/9781118445112.stat03432.pub2
Colwell, R. K., & Chao, A. (2022). Measuring and comparing class diversity in archaeological assemblages: A brief guide to the history and state-of-the-art in diversity statistics. In M. I. Eren & B. Buchanan (Eds.), Defining and Measuring Diversity in Archaeology: Another Step Toward an Evolutionary Synthesis of Culture (pp. 263–294). Berghahn Books.
Courmier, L. T., Nakoinz, O., & Popa, C. N. (2018). Three methods for detecting past groupings: Cultural space and group identity. Journal of Archaeological Method Theory, 25, 643–661. https://doi.org/10.1007/s10816-017-9350-2
Crema, E. R., Kandler, A., & Shennan, S. (2016). Revealing patterns of cultural transmission from frequency data: Equilibrium and non-equilibrium assumptions. Scientific Reports, 6, 39122. https://doi.org/10.1038/srep39122
Crema, E. R. (2015). Time and probabilistic reasoning in settlement analysis. In J. A. Barcelo, & I. Bogdanovic (Eds.), Mathematics in archaeology (pp. 314–334). CRC Press. https://doi.org/10.1201/b18530-20
D’Agata, A. L., & Moody, J. A. (Eds.). (2005). Ariadne's threads: Connections between Crete and the Greek Mainland in Late Minoan III (LM IIIA2 to LM IIIC): Proceedings of the International Workshop Held at Athens, Scuola Archeologica Italiana, 5–6 April 2003. Vol. 3. Scuola archeologica italiana di Atene.
Diachenko, A., & Menotti, F. (2012). The gravity model: Monitoring the formation and development of the Tripolye culture giant-settlements in Ukraine. Journal of Archaeological Science, 39(8), 2810–2817. https://doi.org/10.1016/j.jas.2012.04.025
Diachenko, A., & Sobkowiak-Tabaka, I. (2022). Self-organized cultural cycles and the uncertainty of archaeological thought. Journal of Archaeological Method and Theory, 29, 1034–1057. https://doi.org/10.1007/s10816-022-09548-8
Diachenko, A., Sobkowiak-Tabaka, I., & Ryzhov, S. (2020). Approaching unification and diversity of pottery assemblages: The case of Western Tripolye culture (WTC) ceramics in the Southern Bug and Dnieper interfluve, 4100–3600 BCE. Documenta Praehistorica, 47, 522–535. https://doi.org/10.4312/dp.47.30
Diachenko, A., Rivers, R., & Sobkowiak-Tabaka, I. (2023). Convergent evolution of prehistoric technologies: The entropy and diversity of limited solutions. Journal of Archaeological Method and Theory (this issue).
Dickens, R. S., Jr., & Fraser, M. D. (1984). An information-theoretic approach to the analysis of cultural interactions in the Middle Woodland period. Southeastern Archaeology, 3(2), 144–152.
Driessen, J., & Langohr, C. (2007). Rallying ‘round a “Minoan” past. The legitimation of power at Knossos during the Late Bronze Age. In M. L. Galaty, & W. A. Parkinson (Eds.), Rethinking Mycenaean Palaces II, (pp. 178–189). Cotsen Institute of Archaeology Press.
Drost, C., & Vander Linden, M. (2018). Toy story: Homophily, transmission and the use of simple simulation models for assessing variability in the archaeological record. Journal of Archaeological Method and Theory, 25(4), 1087–1108. https://doi.org/10.1007/s10816-018-9394-y
Eren, M. I., & Buchanan, B. (Eds.). (2022). Defining and measuring diversity in archaeology: Another step toward an evolutionary synthesis of culture. Berghahn Books.
Evans, A. J. (1906). The Prehistoric Tombs of Knossos. I. The Cemetery of Zafer Papoura. II. The Royal Tombs of Isopata. B. Quaritch.
Furholt, M. (2012). Kundruci: Development of social space in a Late Neolithic tell-settlement in Central Bosnia. In R. Hofmann, F.-K. Moetz, & J. Müller (Eds.), Tells: Social and environmental space (pp. 203–220). Rudolf Habelt GmbH.
Gheorghiade, P. & Vasiliauskaite, V. (2023). Digital extras for Entropology Paper (v1.3). Zenodo. 10.5281/zenodo.8243079
Gheorghiade, P. (2020). “A network approach to interaction and maritime connectivity on Crete during the Late Bronze Age – Late Minoan II–IIIB2.” Doctoral Thesis, University of Toronto.
Gjesfjeld, E., Silvestro, D., Chang, J., Koch, B., Foster, J. G., & Alfaro, M. E. (2020a). A quantitative workflow for modeling diversification in material culture. PLoS ONE, 15(2), e0227579. https://doi.org/10.1371/journal.pone.0227579
Gjesfjeld, E., Crema E. R., & Kandler, A. (2020b). Analysing the diversification of cultural variants using longitudinal richness data, OSF Preprints. https://doi.org/10.31219/osf.io/nkfet
Good, I. J. (1953). The population frequencies of species and the estimation of population parameters. Biometrika, 40, 237–264. https://doi.org/10.2307/2333344
Gronenborn, D., Strien, H.-C., Dietrich, S., & Sirocko, F. (2014). ‘Adaptive cycles’ and climate fluctuations: A case study from Linear Pottery Culture in western Central Europe. Journal of Archaeological Science, 51, 73–83. https://doi.org/10.1016/j.jas.2013.03.015
Gronenborn, D., Strien, H. C., & Lemmen, C. (2017). Population dynamics, social resilience strategies, and adaptive cycles in early farming societies of SW Central Europe. Quaternary International, 446, 54–65. https://doi.org/10.1016/j.quaint.2017.01.018
Gronenborn, D., Strien, H.-C., Wirtz, K., Turchin, P., Zeilhofer, C., & van Dick, R. (2020). Inherent collapse? Social dynamics and external forcing in Early Neolithic and modern Southwestern Germany. In F. Riede & P. Sheets (Eds.), Going forward by looking back: Archaeological perspectives on socio-ecological crisis, response, and collapse (pp. 333–366). Berghahn.
Gronenborn, D., Strien, H.-C., van Dick, R., & Turchin, P. (2018). Social diversity, social identity, and the emergence of surplus in western central European Neolithic. In H. Meller, D. Gronenborn, & R. Risch (Eds.), Surplus without the state – Political forms in prehistory. 10th Archaeological Conference of Central Germany, October 19 – 21, 2017 in Haale (Saale) (pp. 201–220). Grafissches Centrum Cuno GmbH and Co.
Habiba, R., Athenstadt, J. C., Mills, B. J., & Brandes, U. (2018). Social networks and similarity of site assemblages. Journal of Archaeological Science, 92, 63–72. https://doi.org/10.1016/j.jas.2017.11.002
Hallager, E., & Hallager, B. P. (Eds.). (1997). Late Minoan III Pottery Chronology and Terminology. Acts of a Meeting held at the Danish Institute at Athens, August 12–14, 1994. Aarhus University Press.
Harper, T. K., Diachenko, A., Rassamakin, Y. Y., Chernovol, D. K., Shumova, V. A., Nechitailo, P., Chabaniuk, V. V., Tsvek, E. V., Bilas, N. M., Pohoralskyi, Y. V., Eccles, L. R., Kennett, D. J., & Ryzhov, S. N. (2021). Combining relative chronology and AMS 14C dating to contextualize ‘megasites’, serial migrations and diachronic expressions of material culture in the Western Tripolye culture, Ukraine. Documenta Praehistorica, 48, 276–296. https://doi.org/10.4312/dp.48.11
Harper, T. K. (2021). The absolute chronology of Tripolye settlements in the Southern Bug-Dnieper and Middle Dnieper regions, ca. 4200–2950 Cal BC. In A. Diachenko, T. K. Harper, Y. Rassamakin, & I. Sobkowiak-Tabaka (Eds.), Data systematization in the Neo-Eneolithic of Southeastern and Central Europe: Essays in honor of Sergej Ryzhov, (pp. 58–78). Institute of Archaeology of the NAS of Ukraine.
Hatzaki, E. (2005). Knossos. The Little Palace: British School at Athens.
Havrda, J., & Charvat, F. (1967). Quantification method of classification processes: Concept of structural entropy. Kybernetika, 3, 30–35.
Hegmon, M., Freeman, J., Kintigh, K. W., Nelson, M. C., Oas, S., Peeples, M. A., & Torvinen, A. (2016). Marking and making differences: Representational diversity in the U.S. Southwest. American Antiquity, 81(2), 253–272. https://doi.org/10.7183/0002-7316.81.2.253
Hill, M. (1973). Diversity and evenness: A unifying notation and its consequences. Ecology, 54, 427–432.
Hillman, B. L. (2013). The clothes i wear help me to know my own power The Politics of Gender Presentation in the Era of Women’s Liberation. Frontiers: A Journal of Women’s Studies, 54(2), 155–185. https://doi.org/10.5250/fronjwomestud.34.2.0155
Huggett, J. (2020). Is big digital data different? Towards a new archaeological paradigm. Journal of Field Archaeology, 45(sup1), S8–S17. https://doi.org/10.1080/00934690.2020.1713281
Jost, L. (2006). Entropy and diversity. OIKOS. Advancing. Ecology, 113(2), 363–375. https://doi.org/10.1111/j.2006.0030-1299.14714.x
Jost, L. (2007). Partitioning diversity into independent alpha and beta components. Ecology, 88(10), 2427–2439. https://doi.org/10.1890/06-1736.1
Justeson, J. S. (1973). Limitations of archaeological inference: An information-theoretic approach with applications in methodology. American Antiquity, 38(2), 131–149. https://doi.org/10.2307/279360
Kandler, A. & Crema, E. R. (2019). Analysing cultural frequency data: Neutral theory and beyond. In A. Prentiss (Ed.), Handbook of evolutionary research in archaeology (pp. 83–108). Springer. https://doi.org/10.1007/978-3-030-11117-5_5
Knappett, C. (2022). Artefact typology as media ecology. Perspectives from Aegean Bronze Age art. In D. Wengrow (Ed.), Image, Thought, and the Making of Social Worlds, Freiburger Studien zur Archäologie & Visuellen Kultur, 3 (pp. 115–137). Heidelberg. https://doi.org/10.11588/propylaeum.842
Kristiansen, K. (2014). Towards a new paradigm The third science revolution and its possible consequences in archaeology. Current Swedish Archaeology, 22, 11–34. https://doi.org/10.37718/CSA.2014.01
Kristiansen, K. (2022). Archaeology and the genetic revolution in European prehistory. Elements in the Archaeology of Europe. https://doi.org/10.1017/9781009228701
Kruts V. (2003). The Tripolye ‘ploschadki’ as a result of ritual house burning. In V. Kruts, A. Korvin-Piotrovskiy, & S. Ryzhov (Eds.), Tripolian settlements-giants. The international-symposium materials (pp. 74–76). Kiev: Institute of Archaeology of the NAS of Ukraine [English translation of the Russian title].
Lévi-Strauss, C. (1955). Triste tropiques. Plon.
Lévi-Strauss, C. (1961). A world on the wane. Criterion Books.
Lipo, C. P., Madsen, M. E., & Dunnell, R. C. (2015). A theoretically-sufficient and computationally-practical technique for deterministic frequency seriation. PLoS ONE, 10(4), e0124942. https://doi.org/10.1371/journal.pone.0124942
Lyman, R. L., & O’Brien, M. J. (2003). W.C. McKern and the Midwestern taxonomic method. University of Alabama Press.
Manning, S. W. (1995). The absolute chronology of the Aegean Early Bronze Age: Archaeology, radiocarbon and history. Sheffield Academic Press.
Markevich, V. I. (1981). Late Tripolye tribes of Northern Moldova. Shtiintsa [English translation of the Russian title].
Mesoudi, A. (2011). Cultural evolution: how Darwinian theory can explain human culture and synthesize the social sciences. University of Chicago Press.
Miller, G. A., & Madow, W. G. (1954). On the maximum likelihood estimate of the Shannon-Wiener measure of information (pp. 54–75). Air Force Cambridge Research Center: Technical Report.
Mills, B. J., Peeples, M. A., Haas, R. W., Jr., Borck, L., Clark, J. J., & Roberts, J. M., Jr. (2015). Multiscalar perspectives on social networks in the Late Prehispanic Southwest. American Antiquity, 80(1), 3–24. https://doi.org/10.7183/0002-7316.79.4.3
Mountjoy, P. A., Burke, B., Christakis, K. S., Driessen, J., Evely, R. D. G., Knappett, C., & Krzyszkowska, O. H. (2003). Knossos: The South House. British School at Athens.
Murray, S. (2021). Big data and greek archaeology: Potential, hazards, and a case study from Early Greece. In C. Cooper, New Approaches to Ancient Material Culture in the Greek & Roman World. Monumenta Graeca et Romana, 27 (pp. 63–78). Brill.
Neiman, F. D. (1995). Stylistic variation in the evolutionary perspective: Inferences from decorative diversity and interassemblage distance in Illinois Woodland ceramic assemblage. American Antiquity, 60(1), 7–36. https://doi.org/10.2307/282074
Nolan, K. C. (2020). Bringing archaeology into the information age: Entropy, noise, channel capacity, and information potential in archaeological significance assessments. Quality and Quantity, 54, 1171–1196. https://doi.org/10.1007/s11135-020-00980-0
O’Brien, M. J., & Lyman, R. L. (2000). Applying evolutionary archaeology. Plenum.
Orton, C. (2000). Sampling in Archaeology. Cambridge University Press.
Paige, J., & Perreault, C. (2022). How surprising are lithic reduction strategies? The information entropy of the modes A-I framework. Lithic Technology. https://doi.org/10.1080/01977261.2022.2113699.
Panek., T. (2019). https://www.levistrauss.com/2019/11/07/blue-jeans-and-the-fall-of-the-berlin-wall/
Perreault, C. (2019). The quality of the archaeological record. University of Chicago Press.
Popham, M. R., Betts, J., Cameron, M., Catling, H. W., Catling, E. A., Evely, D., Higgins, R. A., & Smyth, D. (1984). The Minoan Unexplored Mansion at Knossos. Thames and Hudson.
Popham, M. (1970). The destruction of the palace of Knossos: Pottery of the Late Minoan IIIA Period. Paul Åströms Förlag.
Porčić, M. (2023). Patterns in space and time: Simulating cultural transmission in archaeology. Faculty of Philosophy, University of Belgrade.
Premo, L. S., & Kuhn, S. L. (2010). Modelling effects of local extinctions on culture change and diversity in the Paleolithic. PLoS ONE, 5(12), e15582. https://doi.org/10.1371/journal.pone.0015582
Pressé, S., Ghosh, K., Lee, J., & Dill, K. A. (2013). Nonadditive entropies yield probability distributions with biases not warranted by the data. Physical Review Letters, 111, 180604. https://doi.org/10.1103/PhysRevLett.111.180604
Preston, L. (2004). A mortuary perspective on political changes in Late Minoan II–IIIB Crete. American Journal of Archaeology, 108(3), 321–348.
Quine, V. O. W. (1980). From a logical point of view: Nine logico-philosophical essays (2nd ed.). Harvard University Press.
Renyi, A. (1970). Probability theory. North Holland Publishing.
Ricci, L., Perinelli, A., & Castelluzzo, M. (2021). Estimating the variance of Shannon entropy. Physical Review E, 104, 024220. https://doi.org/10.1103/PhysRevE.104.024220
Rutter, J. (2000). The short-necked Amphora of the post-palatial Mesara. In Ζ Σημανδηράκη (Ed.), Πεπραγμένα Η΄ Διεθνούς Κρητολογικού Συνεδρίου 3 (pp. 2–10). Εταιρεία Κρητικών Ιστορικών Μελετών.
Ryzhov, S. N. (2012). Tripolian pottery of the giant-settlements: Characteristics and typology. In F. Menotti, & A. G. Korvin-Piotrovskiy (Eds.), The Tripolye Culture Giant-settlements in Ukraine, (pp. 79–115). Oxbow Books. https://doi.org/10.2307/j.ctvh1dvmn
Ryzhov, S. (2021). The evolution of Western Tripolye culture in the Southern Bug and Dnieper interfluve. In A. Diachenko, T. K. Harper, Y. Rassamakin, & I. Sobkowiak-Tabaka (Eds.), Data systematization in the Neo-Eneolithic of Southeastern and Central Europe: Essays in honor of Sergej Ryzhov, (34–57). Institute of Archaeology of the NAS of Ukraine [English translation of the Ukrainian title].
Sanders, H. L. (1968). Marine benthic diversity: A comparative study. The American Naturalist, 102(925), 243–282.
Schiffer, M. B. (1987). Formation processes of the archaeological record. University of New Mexico.
Seweryn, M. T., Pietrzak, M., & Ma, Q. (2020). Application of information theoretical approaches to assess diversity and similarity in single-cell transcriptomics. Computational and Structural Biotechnology Journal, 18, 1830–1837. https://doi.org/10.1016/j.csbj.2020.05.005
Shannon, C. (1948). A mathematical theory of communication. Bell System Technical Journal, 27, 379–423, 623–656. https://archive.org/download/pdfy-nl-WZBa8gJFI8QNh/shannon1948.pdf
Shott, M. J. (2010). Size dependence in assemblage measures: Essentialism, materialism, and “SHE” analysis in archaeology. American Antiquity, 75(4), 886–906. https://doi.org/10.7183/0002-7316.75.4.886
Sloman, A. (2013). “Jane Austen’s concept of information (Not Claude Shannon’s)”. http://www.cs.bham.ac.uk/research/projects/cogaff/misc/austen-info.pdf
Tartaron, T. (2008). Aegean prehistory as world archaeology: Recent trends in the archaeology of Bronze Age Greece. Journal of Archaeological Research, 16(2), 83–161. https://doi.org/10.1007/s10814-007-9018-7
Tribus, M. (1961). Thermostatics and thermodynamics: An introduction to energy, information and states of matter, with engineering applications. Van Nostrand.
Tsallis, C. (2009). Introduction to non-extensive statistical mechanics. Springer. https://doi.org/10.1007/978-0-387-85359-8
VanValkenburgh, P., & Dufton, J. A. (2020). Big archaeology: Horizons and blindspots. Journal of Field Archaeology, 45(51), 51–57.
Warren, P., & Hankey, V. (1989). Aegean Bronze Age chronology. Bristol Classical Press.
Willis, A. D. (2019). Rarefaction, alpha diversity and statistics. Frontiers in Microbiology, 10, 2407. https://doi.org/10.3389/fmicb.2019.02407
Wiśniewski, A., Kozyra, C., & Chłoń, M. (2022). Reading the mobility of Late Palaeolithic hunter-gatherers. Case study from the Sowin site complex in relation to Late Palaeolithic sites north of the Sudetes and Carpathians. In I. Sobkowiak-Tabaka, A. Diachenko, & A. Wiśniewski (Eds.), Quantifying Stone Age mobility: Scales and parameters (pp. 47–68). Springer. https://doi.org/10.1007/978-3-030-94368-4_3
Wolda, W. (1981). Similarity indices, sample size and diversity. Oecologia, 50, 296–302. https://doi.org/10.1007/BF00344966
Zaneveld, J. R., McMinds, R., & Thurber, R. V. (2017). Stress and stability: Applying the Anna Karenina principle to animal microbiomes. Nature Microbiology, 2, 17121. https://doi.org/10.1038/nmicrobiol.2017.121
Acknowledgements
The authors would like to thank Carl Knappett, Metin I. Eren, and three anonymous reviewers for reading our earlier drafts and providing valuable feedback. This feedback allowed us to greatly improve its final publication.
Funding
Open Access funding provided by University of Helsinki (including Helsinki University Central Hospital). Vaiva Vasiliauskaite acknowledges the support of the European Union—Horizon 2020 Program under the scheme “INFRAIA-01–2018-2019—Integrating Activities for Advanced Communities,” Grant Agreement no. 871042, “SoBigData + + : European Integrated Infrastructure for Social Mining and Big Data Analytics” (http://www.sobigdata.eu).
Author information
Authors and Affiliations
Contributions
All authors contributed to writing the manuscript. PG, VV, and HP prepared the maps, figures, and tables. All authors reviewed and edited the manuscript.
Corresponding author
Ethics declarations
Competing Interests
The authors declare no competing interests.
Ethics Approval
The authors are responsible for correctness of the statements provided in the manuscript.
Consent to Participate
Not applicable.
Consent for Publication
Both authors gave explicit consent to submit an article.
Conflict of Interest
The authors declare no competing interests.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Gheorghiade, P., Vasiliauskaite, V., Diachenko, A. et al. Entropology: an Information-Theoretic Approach to Understanding Archaeological Data. J Archaeol Method Theory 30, 1109–1141 (2023). https://doi.org/10.1007/s10816-023-09627-4
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10816-023-09627-4