
Abstract
In the modern digital age, companies need to be able to quickly explore the process innovation affordances of digital technologies. This includes exploration of Machine Learning (ML), which when embedded in processes can augment or automate decisions. BPM research suggests using lightweight IT (Bygstad, Journal of Information Technology, 32(2), 180–193 2017) for digital process innovation, but existing research provides conflicting views on whether ML is lightweight or heavyweight. We therefore address the research question “How can Lightweight IT contribute to explorative BPM for embedded ML?” by analyzing four action cases from a large Danish manufacturer. We contribute to explorative BPM by showing that lightweight ML considerably speeds up opportunity assessment and technical implementation in the exploration process thus reducing process innovation latency. We furthermore show that succesful lightweight ML requires the presence of two enabling factors: 1) loose coupling of the IT infrastructure, and 2) extensive use of building blocks to reduce custom development.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
In the current digital age, companies are faced with an ever-growing plethora of affordances for innovating and improving business processes in both incremental and radical ways. This situation of opportunity abundance has created the need for fast exploration of digital process affordances in addition to the traditional problem-solving focus on existing processes (Grisold et al., 2019; Rosemann, 2014). While much IS process innovation research predates the digital age, exploratory process innovation research has picked up in the BPM community in recent years under the term of Explorative BPM. Explorative BPM concerns opportunity rather than problem-driven process change with one key source of opportunities being those arising from new digital technologies (Grisold et al., 2019). Explorative BPM research has so far focused on digital technologies at a general level and considered the opportunity identification stage (Grisold et al., 2022; Gross et al., 2021), implementation success factors (Baier et al., 2022), and digital capabilities (Kerpedzhiev et al., 2021). Machine Learning (ML) is one technology that offers process innovation affordances by being embedded into business processes and augmenting or automating decisions and actions (Davenport, 2018). However, in practice, companies are struggling to successfully deploy ML (Davenport & Malone, 2021; Paleyes et al., 2022). ML is a complex technology, typically the result of extensive custom development and firmly situated in the domain of IT. It thus seems incompatible with the need for fast exploration and process (rather than technology) focus of explorative BPM.
Previous research has leveraged the concept of lightweight IT (Bygstad, 2017) to examine the role of IT in digital process innovation. This research suggests that successful digital process innovation should use lighter engineering and lightweight IT (Schmiedel & Brocke, 2015; Baiyere et al., 2020; Bygstad & Øvrelid, 2020) that is aligned with the heavyweight digital infrastructure, achieved through boundary resources and loose coupling (Bygstad & Øvrelid, 2020). Existing research, however, provides conflicting views of whether ML can be viewed as lightweight IT. One stream of research takes the traditional view of ML and suggests that successful ML requires rigorous and systematic engineering (e.g., Lavin et al., 2022), placing it firmly in the realm of heavyweight IT. Another stream of research suggests that recent innovations in ML platforms and tooling will make it possible for users with domain knowledge to build their own systems (e.g., Hutter et al., 2019), thus placing ML in the realm of lightweight IT. Having identified this tension and uncertainty in the existing conceptualization of ML, we set out to answer the following research question:
How can Lightweight IT Contribute to Explorative BPM for Embedded ML?
To answer the research question, we examined four embedded ML projects at a large Danish manufacturer on the basis of ongoing engaged scholarship. The projects all attempted to treat ML as lightweight IT, but achieved different degrees of success in doing so. We find evidence of successful lightweight ML, thus showcasing that the traditional idea of ML as a heavyweight technology need not be true. Making use of lightweight ML resulted in significantly speeding up the exploratory innovation process compared to heavier approaches. We further show that this speeding up is due to 1) loose coupling, which enables exploratory work to be carried out independently of heavyweight IT, and 2) the extensive use of building blocks, allowing steps of the traditional ML process to be skipped. Our findings thus contribute to explorative BPM by providing insights into how to speed up the assessment and technical implementation phases of explorative BPM (Rosemann, 2014).
2 Background
2.1 Explorative BPM in a Digital Age
Business Processes Management (BPM) is a holistic approach with the goal of ensuring effective and efficient business processes: the coordinated sequences of work involved in delivering products and services (Dumas et al., 2013). Improving process performance is a key concern of BPM and it can be approached using means ranging from incremental (e.g., Lean or Six Sigma) to radical (e.g., BPR). Although IT has long been recognized in BPM as a key enabler of process improvement and innovation (Davenport & Short, 1990), BPM has come under critique for failing to explore (Benner & Tushman, 2003) and take advantage of the many process innovation affordances offered by new digital technologies (Grisold et al., 2019; Rosemann, 2014). One proposed explanation for this failure is that there are significant differences in the underlying logics and assumptions of BPM and digital innovation, with the implication being that BPM should reconsider and update its foundations and methods (Baiyere et al., 2020; Mendling et al., 2020). One stream of research has started tackling this challenge under the header of explorative BPM, focusing on how to explore opportunities for process innovation (Rosemann, 2014). This focus stands in contrast to traditional, exploitative BPM, which takes outset in problems within existing processes in the search for process improvement opportunities (Grisold et al., 2019; Rosemann, 2014). Explorative BPM is characterized by being opportunity-driven and leveraging opportunities to either reengineer existing processes or create new processes (Grisold et al., 2019). Exploration should be a continuous process (Grisold et al., 2019), covering the identification, assessment, and implementation of process innovation opportunities, and the aim should be for organizations to improve exploration speed or process innovation latency (Rosemann, 2014).
Other work revisiting the foundation of BPM has suggested that lighter and more flexible approaches to BPM are required in the digital age. Baiyere et al., (2020) suggested a shift in logic towards light rather than strongly modeled processes, flexible rather than aligned infrastructure, and mindful actors rather than routine followers. The use of lightweight IT for process innovation was suggested by Bygstad & Øvrelid, (2020), and they further clarified the need for alignment between the digital infrastructure and lightweight IT to enable successful digital process innovation. Lightweight IT is defined as “a knowledge regime, driven by competent users’ need for solutions, enabled by the consumerisation of digital technology and realized through innovation processes” (Bygstad, 2017). It is characterized by a focus on work process support, emergent architectures, and light and standard technologies (Bygstad, 2017). Lightweight IT is juxtaposed with Heavyweight IT, defined as “a knowledge regime, driven by IT professionals, enabled by systematic specification and proven digital technology and realized through software engineering” (Bygstad, 2017). Heavyweight IT is the realm of traditional IT delivery, and is characterized by a focus on transaction processing, integrated architectures, and proven technologies (Bygstad, 2017).
As lightweight IT operates largely outside the traditional IT department, it is not subjected to the same strict IT governance as heavyweight IT, which contributes positively to innovation and experimentation. Nonetheless, lightweight IT is often reliant on heavyweight IT for access to data and functionality, which can pose challenges for Lightweight IT as the knowledge regimes operate at different speeds. A solution to this challenge has been proposed using the notion of coupling, suggesting that lightweight IT and heavyweight IT should be loosely coupled and aligned rather than integrated, both technically (e.g., in terms of IT architecture) and organizationally (e.g., in terms of developer and user communities) (Bygstad, 2017; Bygstad & Øvrelid, 2020). Coupling signifies the degree and nature of interdependence between two systems. Loose coupling refers to systems exhibiting individual identity and separateness, that are weakly interacting or doing so with minimal dependence, thus exhibiting and requiring little coordination (Weick, 1976). Tight coupling refers to the opposite situation, where systems are strongly interacting and highly interdependent. One of the benefits of loosely coupled systems is that they allow the addition or removal of components to the system without significant impact on other components and the overall system (Weick, 1976).
2.2 Embedded ML to Improve Business Processes
The role of analytics and ML in business process improvement is changing with ML increasingly being embedded in business processes (Davenport, 2018). Traditionally, analytics and ML have been used offline in business process work by process analysts or data scientists to discover process insights (Davenport et al., 2010) that could be used for either control or redesign actions. A prime example of this offline approach is using either process mining (van der Aalst, 2012) or business process analytics (Lang et al., 2015) to discover bottlenecks in processes, based on which resources can be added or processes can be redesigned. Embedded ML, on the other hand, concerns leveraging an ML system as part of the business process at run-time. Improving business processes with embedded ML thus requires the development and implementation of an ML system along with a redesign of the process to take advantage of the ML system. Examples falling under the header of embedded ML from the BPM community include recent advances in process mining such as Process Forecasting (Poll et al., 2018) and Predictive Process Monitoring (e.g., Teinemaa et al., 2019). Our use of the term Embedded ML in business processes is, however, broader than these two areas as it covers any situation in which an ML system is used as part of the execution of a business process, notwithstanding how it is used.
The role of embedding ML and AI in business processes has been primarily conceptualized as either automating or augmenting tasks rather than the whole process (Benbya et al., 2021; Sedera et al., 2016). However, task-level changes can enable redesigning the process (Enholm et al., 2021; May et al., 2020) or require either addition of new tasks or changes in task composition and structure (Grønsund & Aanestad, 2020; Kunz et al., 2022). The value and impact of ML and AI from a process perspective is in improving process efficiency in terms of increased productivity and reduced errors (Enholm et al., 2021).
2.3 Machine Learning Systems: Heavy or Light?
Machine Learning is a subset of artificial intelligence concerned with using computers to conduct tasks based on learning from data (Enholm et al., 2021). Common tasks include clustering, classification, regression, making recommendations, or prescribing actions. ML is different from traditional software in that 1) its output is probabilistic, with the affordances offered depending on the particular dataset used for learning, and 2) it has models and datasets as key artefacts (Paleyes et al., 2022). ML is further distinguished from previous iterations of AI in that it often possesses greater autonomy and is more difficult to understand (Berente et al., 2021). Organizational decision-making using ML thus involves humans to a smaller extent and offers less insight into the reasoning behind decisions or recommendations made by ML, essentially rendering the technology a black box (Berente et al., 2021).
As a result of these differences, the ML development process differs from traditional software engineering, having more in common with methods from Decision Support Systems. Process models conceptualize ML systems development as an iterative process (Lavin et al., 2022; Martínez-Plumed et al., 2019; Microsoft, 2023; Wirth & Hipp, 2000), concerned with four major groups of activities: 1) Problem Framing, where the business problem is understood and translated into an ML problem, 2) Data Acquisition & Preparation, where the necessary data is acquired and preprocessed, 3) Model Development, where an ML model is trained and evaluated using data, and 4) Deployment, where the ML model is turned into an ML system, deployed, and integrated with other systems if required, resulting in a usable IT artefact.
Traditionally, ML research and practice have been narrowly focused on the model, developed by a specialized data scientist or statistician, and have treated deployment as a simple matter of implementation, often done by IT. The main challenge in this view is thus to find the right combination of data and model that yields useful analytical capabilities, measured in terms of quantitative performance metrics. Partly responsible for this focus is the fact that many ML initiatives are stopped following Model Development due to a failure to obtain satisfactory analytical performance. Following challenges faced in practice in the Deployment stage, where models developed either were difficult to integrate with the existing infrastructure or failed to solve the intended business problem (Davenport & Malone, 2021), focus has shifted towards the ML system rather than the model (Lavin et al., 2022; Ratner et al., 2019). It has been recognized that ML models are only a small part of the complex infrastructure required to deploy ML (Sculley et al., 2015). This research stream has taken an engineering perspective and focused on the development of new tools (e.g., Breck et al., 2019), infrastructure (e.g., Phillips-Wren et al., 2021), and systematic methods (Lavin et al., 2022). Calls have likewise been made for increased rigour in ML development, which should borrow from well-established system engineering methods (Lavin et al., 2022).
Concurrently with the calls for increased rigour, other research streams have worked with the assumption that the solution to greater deployment and adoption of ML is to democratize it and allow non-specialists to develop ML systems. The democratization is enabled by technological advancements that automate parts of the ML process (e.g., Hutter et al., 2019; Uzunalioglu et al., 2019) and training of employees (Lefebvre et al., 2021), thus speeding up the development process and making ML accessible for non-experts with greater knowledge of the problem domain. These developments contribute to making ML a lighter technology by reducing the need for extensive engineering and moving technology development closer to the use domain.
Summarizing our review of the literature, we see that best-practice in digital process innovation is to use lightweight IT and focus on user needs rather than turning initiatives into large, slow, and heavy engineering projects. ML is increasingly embedded in processes to improve their performance, but the historical use of ML and parts of the current discourse suggest that it belongs to the domain of heavyweight IT with its focus on engineering. However, technological advancements in ML are increasingly making it possible to treat ML as a lighter technology and reducing the need for engineering. Thus, current literature is unclear as to whether ML should be conceptualized as heavy or light, which in turn will have large implications for its role in exploratory process innovation.
3 Analytical Framework
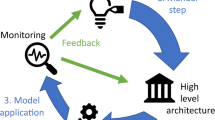
Our review of the literature suggests that ML as a technology has characteristics associated with both lightweight and heavyweight IT. The development culture and application domain point towards lightweight IT, while the competencies required and the nature of ML as a technology point towards heavyweight IT. Other aspects are less clear, as data science work is traditionally done outside heavyweight IT delivery either by Center of Excellences, consultants, or in business units, utilizing development methods tailored to ML. To clarify the issue of the role of lightweight IT in embedded ML, we suggest that a more detailed understanding of embedded ML is necessary, which requires opening the black box of the ML development process and examining it in relation to its context. To accomplish this, we propose the analytical framework in Fig. 1 to guide our analysis of the cases. The framework builds on and synthesizes our review of the literature on explorative BPM, embedded ML, and lightweight IT.

Analytical framework
As illustrated in Fig. 1, we adopt a processual view of embedded ML in the context of explorative BPM. Explorative BPM, concerned with the opportunity-driven exploration of digital technologies (Grisold et al., 2019; Rosemann, 2014), is part of the context and acts as a trigger for the embedded ML development process with the goal of discovering process innovation affordances of embedded ML for a particular use case. To conceptualize the embedded ML development process in more detail, we leverage the typical four-stage development process model of 1) Problem Framing, 2) Data Acquisition and Preparation, 3) Model Development, and 4) Deployment. The embedded development process produces an outcome in the form of ML models and systems, as well as insights into the process innovation affordances they offer while consuming time and resources. In terms of the success of the outcome, we focus on two aspects: 1) whether the ML artefacts provide process innovation affordances, and 2) the speed of exploration, i.e., how quickly the affordances are explored. From a business perspective, the outcome is a success if the ML artefacts provide process affordances that enable redesign and improvement of the business process. From an innovation perspective, not all exploratory projects are going to result in process innovation affordances, so the speed at which opportunities can be assessed is important (Rosemann, 2014).
To analyze and explain the differences in outcome, we leverage the concepts of coupling and building blocks. As emphasized in the work of Bygstad, (2017) and Bygstad & Øvrelid, (2020), the lightweight development process relies on data and functionality in the heavyweight IT systems, thus introducing a certain coupling between the heavyweight IT and lightweight IT systems. Tight coupling makes the development process dependent on heavyweight processes and resources, reducing the speed of the initiative to that of the heavyweight systems (Bygstad, 2017). We further leverage the notion of building blocks, which we define as “existing socio-technical components that are used in the development process as part of the solution”. One example of a building block is a boundary resource (Ghazawneh & Henfridsson, 2013), which consists of software tools and regulations that provide external access to a platform, including a heavyweight IT infrastructure. Other examples include software-as-a-service, such as that offered by cloud vendors, or other lower-level software components. Building blocks are significant, as innovation (including the development of new software systems) mostly happens as a result of recombination of existing components (Arthur, 2009; Henfridsson et al., 2018). Along similar lines, Simon, (1996) noted that the evolution of complex forms is more likely when leveraging “intermediate stable forms”. Relying on configuration of standard technologies to facilitate digital process innovation, as suggested in recent literature (Schmiedel & Brocke, 2015; Bygstad & Øvrelid, 2020), amounts to leveraging very high-level building blocks in the development process.
In our analytical framework, the lightweight or heavyweight nature of embedded ML is thus influenced by 1) its context, 2) characteristics of the development process, including the use and nature of building blocks, and 3) the degree of coupling to heavyweight IT. While the presented framework suggests that embedded ML can be treated as lightweight IT in the right context, we still lack empirical evidence of embedded ML as lightweight IT. Additionally, we need to understand in which context and to what extent treating ML as lightweight IT is possible and, most importantly, whether doing so leads to improved outcomes for the exploratory initiatives.
4 Method
4.1 Research Approach: Engaged Scholarship & Action Cases
The research approach was one of engaged scholarship (Van de Ven, 2007) in the form of a series of action cases (Braa & Vidgen, 1999) aimed at both understanding and intervening. The lead author was engaged with the case company as part of a larger Action Design Research (Sein et al., 2011) project focused on process improvement using embedded ML, which provided access to rich empirical material gathered both as an observer and a designer. Combined observation and intervention in an organizational context is a key characteristic of action cases (Braa & Vidgen, 1999) and is considered an appropriate research strategy in pragmatist IS research (Ågerfalk, 2010; Goldkuhl, 2012). The case company is a large manufacturer with a strong process orientation, widely recognized as a world leader in its domain, and thus strongly capable in exploitative BPM. In recent years, the company has made significant investments in exploratory capabilities by establishing new organizational units, investing in IT infrastructure, and running many exploratory innovation initiatives. The lead author’s activities made up a small part of these exploratory innovation initiatives and consisted of the participation in a total of six projects. During this participation, the lead author was employed in academia, but was sponsored by the case company. The lead author had an employee ID card, was able to access the organization freely, and collaborated with company employees in the innovation initiatives. The second and third authors were not affiliated with the case company and thus played the role of outsiders who could challenge interpretations and contribute to reducing bias (Robey & Taylor, 2018).
To answer our research question, we selected and analyzed four of these exploratory projects. Selection criteria for the initiatives were that they 1) concern embedded ML, 2) aim to improve process performance, and 3) be conducted outside traditional IT delivery, thus at least attempting to be lightweight. Of the six projects, one was not selected for analysis as it did not end up containing an ML component. Another project was dropped during analysis for reasons of brevity, as the findings were similar to that of the Engineering Design Rework Reduction case. Table 1 presents an overview of the cases selected. Below, we elaborate on the case context and our data collection and analyses.
4.2 Case Context
The case organization is a large Danish manufacturer currently undergoing a digital transformation. With a long history as a manufacturer of physical products, the company has started providing digital products and is working on transforming its operations to leverage digital technologies. An organizational unit has been established to own the digital transformation of operations, consisting of several subunits responsible for specific strategic initiatives. Industry 4.0 is one of these strategic initiatives aimed at improving productivity and responsiveness in the manufacturing processes. In the Industry 4.0 initiative, data and analytics are seen as offering potential for significant process improvement and has been the subject of several R&D initiatives and pilots. To support this transformation, Operations IT has focused on reducing technical debt and building platforms. As the existing enterprise data platform focused on marketing did not provide appropriate support for data initiatives in manufacturing, Operations IT established a small subunit that developed and operated an operations data platform leveraging modern cloud services. The data platform was envisioned as a self-service platform, where IT teams in Operations IT would deliver data, enabling data initiatives to work decoupled from the process execution-focused IT infrastructure. The data platform provided access to data, self-service clusters capable of processing big data, and several services to support the machine learning process, such as automated model training and automated deployment. As part of establishing the data platform, several data pipelines were built to transport data from the existing digital infrastructure to the data platform, but most data were still siloed in individual systems.
4.3 Data Collection & Analysis
Data was collected in 2021 and 2022 primarily using participative observation, although the nature of participation varied from case to case (see Table 1). In one case (Engineering Design Rework Reduction) the first author participated as an expert from the organization on ML and active engagement thus consisted primarily of participating in discussions and advising. In the other three cases, the first author participated more actively in the development process, with engagement ranging from being a (co-)owner and designer of the development process to participating in parts of the process. Despite the different roles assumed by the first author, all of the cases featured in-context action and observation and had the dual goals of obtaining an understanding of the context and contributing to change, as is characteristic of action cases (Braa & Vidgen, 1999). To facilitate obtaining understanding, the first-hand observation and experiences in the four initiatives were documented using field notes, which represented a key source of data. The field notes focused on the rationale and improvement goals of the projects, activities undertaken in the ML development process and the actors engaged, the design of the ML models and artefacts, as well as the surrounding IT architecture. In addition to the field notes, we collected supporting data in the form of relevant documents, presentations, diagrams of IT architectures, and we had access to the IT artefacts and their underlying source code.
To analyze the data, we relied on an abductive process. The aim of abduction is the construction of a plausible and coherent explanation for “unanticipated” or “surprising” empirical findings (Dubois & Gadde, 2002; Sætre & van de Ven, 2021). The process was triggered by the observation that while the four projects had attempted to treat ML as lightweight, they had not all succeeded. To arrive at an explanation, we conducted an analysis of our data where we iteratively refined our analytical framework and explanation based on engagement with literature and our empirical material.
Our analysis process consisted of five steps, summarized in Table 2. First, we read through field notes and documents to construct an initial case description. The initial description focused on 1) the context and motivation of the exploratory initiative, 2) the activities and actors in the development process, and 3) the project outcome. Alongside the case description, we also developed a representation of the IT architecture for each of the projects. Second, we conducted initial analyses and discussions of the case descriptions and IT architectures. This led us to identify the nature of coupling between heavyweight and lightweight IT as a potential explanation. Third, we constructed an initial version of our analytical framework and reanalyzed the projects using the coupling lens. We compared and contrasted the cases and found that coupling seemed to be an important factor in the success of the projects. However, it was not sufficient to explain the differences in project outcomes. Fourth, we reexamined our empirical material, attempting to identify additional factors that could explain the differences in outcomes. This involved systematically going through each element of our analytical framework for the cases and looking for differences that could be linked to the outcome. We first examined factors associated with the context, such as the goal, the nature of ML use (augment vs. automate), the driver of the project (business vs. IT), and the nature of the selected process. This was followed by an examination of factors related to the development process, including activities, actors, and technology choices. As a result of this process, we identified differences in the technology choices made during the development process as a potential factor: some of the projects required custom development, whereas others relied on connecting existing services. We conceptualized this as the use of building blocks and modified our analytical framework, thus arriving at the final version presented in Section 3. Fifth, we once again re-analyzed our cases to assess our new explanation and found that it was sufficient in explaining the differences in outcomes. The two identified factors provided a parsimonious explanation that had backing in existing research, and adding additional factors added little further insight. At this step, we also assessed rival explanations to see whether they contained similar explanatory power. As examples, we assessed whether differences in how ML is used (i.e., augmentation vs. automation use cases) or increased experience with ML could explain the differences in outcomes. In both cases, these rival explanations were less supported by the empirical evidence. As a result of this analysis, we ended up having identified two factors that were main drivers of the outcomes. Nonetheless, a myriad of other factors will also have influenced the outcomes to a lesser extent. Examples of these factors include aspects such as management support, project team composition, and data quality, in addition to the rival explanations mentioned previously.
5 Cases
5.1 Case 1: Engineering Design Rework Reduction
5.1.1 Context
The first initiative took place in a manufacturing engineering department responsible for designing and producing manufacturing equipment. In the current experience-based process, an equipment design is developed by engineers, manufactured, and then subjected to extensive testing to ensure that it can produce products of acceptable quality. Initial designs, however, rarely pass testing, and thus several expensive iterations are required to reach an acceptable design. The existing process was struggling to meet its strategic output targets, with the amount of rework identified as a main culprit. The exploratory initiative aimed at reducing rework was initiated as IT managers saw potential in using data to improve the engineering processes, while a vendor had offered to conduct a three month PoC in hopes of becoming a future innovation partner. As a result, a vendor-led initiative was started focused on using data to augment design decisions with the goal of reducing rework. Figure 2 provides an overview of the case by means of the analytical framework.

Analytical framework applied to the engineering design rework reduction case
5.1.2 Embedded ML Development Process
The ML development process was exploratory and focused initially on Problem Framing to identify a good use case for the data. After several bouts of engaging process stakeholders and subject matter experts, two related use cases had been prioritized for model development: 1) predicting the number of times a design will fail testing and 2) predicting the probability of a particular test failure. Initial models were quickly developed using Automated ML and design master data, which was readily available, but both models failed to deliver satisfying predictive performance. Concurrently, work was conducted to extract more detailed design data from the CAD system to be used in a second iteration of model development. After considerable delays in extracting CAD data, new models were developed, but the result was still non-satisfactory performance, as there was simply not enough signal in the data.
5.1.3 Coupling to Heayweight IT
While several of the data sources were accessible in a loosely coupled manner, the initiative as a whole was characterized by tight coupling to heavyweight IT due to the CAD data requirements. The design master data was available via self-service BI views and could thus easily be extracted and updated as required by the participants of the initiative. The CAD data was available via a proprietary API, which resulted in tight coupling. Access to the API required licenses that had to go through slow IT approval processes. Additionally, as the API was a generic vendor API, it was not designed to extract the data that was relevant for the company’s use of the system. Developing the data extraction job was thus complex and required competencies from the heavyweight IT team.
5.1.4 Use of Building Blocks
The development process made some use of building blocks in terms of data and model training. Data acquisition and preparation relied on the existing BI views and the CAD data API, but developing the data extraction job for the CAD data API remained a major custom development task. Model development utilized an Automated ML component, which automates the model training part of the process, but leaves the model-specific data processing and model evaluation to the data scientist.
5.1.5 Outcome
The initiative was ultimately not successful in building a viable ML model and use case, even though what was initially scheduled for a 12-week project was extended for another four weeks. It is illustrative of the typical slow and heavyweight nature of ML initiatives, where considerable time, experimentation, and expertise are required to build ML models and discover whether they are useful. While the data scientists did use Automated ML to speed up model development, the speed gained was dwarfed by the slowing down caused by tight coupling to the CAD system, which ended up delaying the whole project.
5.2 Case 2: Engineering Design Cost Prediction
5.2.1 Context
The second initiative took place in the same manufacturing engineering department, however, it had a considerably smaller scope than the first. Initiated by a single engineer, the initiative focused on predicting the costs of making a specific design decision. In the design process, designers have to choose between different equipment design concepts, a decision that is made partly based on an estimate of the cost of the equipment. The existing cost estimate used to choose the design concept was based on heuristics that, while simple, resulted in wildly inaccurate cost estimates. The initiating engineer speculated that ML could improve on the existing cost estimates and, as a result, set out to explore the potential of ML for accurately predicting design costs. Figure 3 provides an overview of the case by means of the analytical framework.

Analytical framework applied to the engineering design cost prediction case
5.2.2 Embedded ML Development Process
The initiative covered all stages of the ML process. Problem framing was carried out by the engineer in collaboration with colleagues. Afterward, the engineer single-handedly completed data acquisition and model development on his company laptop using self-service BI tools to extract design master data and historical cost data from existing BI views. After some experimentation, the engineer managed to develop a model that outperformed the existing heuristic by more than 60% and reached out to an IT engineer and a data scientist (the first author) to get support for deployment. The engineer had developed a prototype web application where users could enter design master data and get cost estimates. After a few architecture workshops, the model was deployed as an API via a GUI, leveraging functionality in the data platform. Concurrently, the web application was refactored and deployed on an existing data application deployment platform offered by the data science CoE.
5.2.3 Coupling to Heayweight IT
Model development was loosely coupled from heavyweight IT, as the ability to manually extract data via existing self-service BI tools meant that no support was required from heavyweight IT. Deployment was not coupled to heavyweight IT at all. While atypical, it was possible as the ML system relied on manual data input rather than data from heavyweight systems. Similarly, the choice to use existing lightweight deployment platforms meant that the system was deployed outside heavyweight IT.
5.2.4 Use of Building Blocks
The development process leveraged two major building blocks: 1) existing BI views and 2) the deployment platforms. The presence of BI views that were already in use meant that model development could start with a relatively solid data foundation and thus reduced the efforts needed to extract, clean and preprocess data. Similarly, the existing data platform provided the ability to quickly deploy models as APIs, and the lightweight data application hosting platform meant that the infrastructure required for deployment was already in place. Model development also made use of building blocks but did so using generic lower-level components, including the algorithms and metrics present in open-source ML libraries.
5.2.5 Outcome
The initiative resulted in the development and deployment of an ML system that was quantitatively evaluated to be considerably superior to the existing heuristic and thus had the potential to significantly reduce costs and increase predictability. The application was presented to process leadership with positive results, and a decision was made to continue implementation of the use case. The initiative also illustrated how a relatively small team was capable of developing and deploying the ML system without significant friction from the heavyweight IT infrastructure. While deployment was lightweight and fast, the process as a whole was not. The custom model development drew on data science expertise and required several bouts of experimentation, resulting in medium speed as the overall outcome.
5.3 Case 3: Closed-loop Control of Machines
5.3.1 Context
The third initiative took place in a manufacturing R&D department responsible for running tests and experiments on manufacturing equipment and conducting process R&D. While the manufacturing process was already highly automated and efficient, significant productivity improvements were still expected as part of the company’s Industry 4.0 strategy. A roadmap for the usage of data and analytics to further improve the process had been developed. An envisioned future use case of ML was to optimize the quality of the production process continuously by automatically adjusting machine settings. Early research had shown promising results in using ML to compensate for variations in the material used, thus leading to improved product quality, albeit at a small scale. However, this research took place without the involvement of IT, and thus the solution and IT architecture developed was not scalable. With IT expecting future demands for solutions leveraging ML-enabled control, a collaboration with IT was established to explore scalable solutions that were interoperable with the existing IT infrastructure. Figure 4 provides an overview of the case by means of the analytical framework.

Analytical framework applied to the Closed-loop control of machines case
5.3.2 Embedded ML Development Process
The ML development process was focused on deployment rather than model development and made use of the model developed in previous R&D. Using the existing model meant that the initiative could skip data acquisition and model development as illustrated via the arrow on Fig. 4. Deployment used the data platform and standard cloud services configured for the use case. A data pipeline was developed using SaaS that extracted the necessary data for predictions from the manufacturing execution system (MES) and moved it to the data platform. The model was deployed as a stream processing job on the data platform that received data from the data pipeline, made predictions, and used the predictions to derive new machine settings. The machine settings were then updated automatically via calls to the MES, which had the ability to update machine settings.
5.3.3 Coupling to Heayweight IT
The initiative was loosely coupled to the heavyweight systems, both in terms of accessing data and functionality. The MES and the ML system were integrated asynchronously, thus ensuring that the MES system was not dependent on the ML system. Accessing data from the MES was possible via an inhouse API, enabling self-service construction of a data pipeline. The model itself was deployed in a self-service fashion using the data platform and thus had no direct integration with heavyweight IT. Similarly, the MES exposed a machine setting adjustment capability as an API, thus allowing the ML system to control machines through API calls.
5.3.4 Use of Building Blocks
The development process made extensive use of building blocks in terms of the data, models, and system components. While data pipelines were built as part of the project, they relied on the presence of an existing API that provided access to the data generated by the production process. Similarly, model development relied on an existing model training script that was repurposed on a new dataset to generate the model. Lastly, deployment relied on both the data processing infrastructure and job scheduling provided by the data platform to deploy the model and existing APIs to allow the ML system to interact with the production machines.
5.3.5 Outcome
The initiative resulted in a successful PoC that demonstrated the feasibility of ML-based closed-loop control of the machines. The use case became one of a number of strategic use cases in the Manufacturing R&D unit, and plans were made to invest in further developing and scaling the use case. While significant R&D work remains before the use case is ready for scaled implementation, the development and implementation of the PoC were conducted by a small team in the space of a two-week development sprint. This was made possible by using components in the form of the existing model, the data platform, and standard SaaS components. Additionally, the initiative had very few external dependencies thanks to the previous work of turning the MES into a platform by API-enabling it. Although the initiative did not only use standard technologies, as evidenced by the existing custom-developed model, it had many of the characteristics of lightweight IT.
5.4 Case 4: Data Quality Anomaly Detection
5.4.1 Context
The fourth initiative took place in IT in the data platform team, which was responsible for operating the data platform and providing access to data for analytical initiatives. Experience with several analytics initiatives using the data platform quickly led to the realization that much of the data in the platform had significant quality problems. The result of these data quality issues was, in the best case, that significant time had to be spent on data cleaning in analytical initiatives. In the worst case, a large part of the data collected was rendered invalid. Sparked by discussions in the data platform team on the need for a process to monitor and secure data quality, a small-scale initiative was started to explore the opportunities of available technology to provide support for a data quality monitoring process. The vision for the initiative was to improve data quality by proactively monitoring data pipelines for issues, using an automated and scalable monitoring solution built on the concept of anomaly detection, followed by detailed manual investigations in case of detected anomalies. Figure 5 provides an overview of the case by means of the analytical framework.

Analytical framework applied to the data quality anomaly detection case
5.4.2 Embedded ML Development Process
The ML development process focused on deployment and was carried out by a single developer (the first author) with sparring from the data platform team. The development process differed from the other cases, as it made use of off-the-shelf available ML-as-a-Service (MLaaS). Making use of MLaaS allowed the development process to skip the training data acquisition phase, as well as the following model development phase as illustrated on Fig. 5 via the arrow. Deployment consisted of provisioning, configuring, and integrating the MLaaS with the data platform through batch jobs scheduled on the data platform. Deployment started out with a single initial data source and was later expanded. For sending notifications when anomalies were detected, a SaaS alerting solution that was already in use in the organization and compatible with the MLaaS software was used.
5.4.3 Coupling to Heayweight IT
Development of the system took place without direct interaction with the heavyweight IT infrastructure, which was made possible by leveraging the data platform. The necessary data was available in the data platform as the result of previous work to construct data pipelines responsible for moving data from the heavyweight systems to the data platform in a batch or streaming process, thus presenting a case of loose coupling.
5.4.4 Use of Building Blocks
The development process relied extensively on existing components with custom development limited to a simple data aggregation job and component integration. Data was available using the existing data pipelines that were deployed using the data processing infrastructure in the data platform. The ML component consisted of an ML-as-a-Service, thus abstracting away both model development and deployment. System Development was similarly reduced mainly to the configuration of a standard UI provided in the MLaaS.
5.4.5 Outcome
The initiative resulted in the development and deployment of a successful PoC that was quickly scaled to cover all data sources in the data platform. During its operation, it managed to identify and provide alerts for several data quality incidents that were resulting in data losses and thus allowed the data platform team to take remedying actions faster. The solution was developed in a short timeframe by a single developer through loosely connecting existing components in a non-invasive manner, thus bearing many of the characteristics of lightweight IT.
5.4.6 Summing up
Our four cases dealt with different challenges, but all of them relate to the same exploratory process. As shown in Table 3, the outcomes vary, from slow to fast, and we have shown in the previous sections how this can be explained by combinations of coupling, the use of building blocks and the predominance of lightweight versus heavyweight IT.
The cases demonstrated that (i) it is possible for ML to be lightweight, and (ii) the speed of lightweight ML projects was higher. This was illustrated by the Closed-loop Control of Machines and Data Quality Anomaly Detection cases. Both cases were focused on improving processes and carried out in organizational units responsible for processes. At the same time, they were able to develop and test PoCs of ML systems with few resources and in short time frames. The same was to a lesser extent true of the Engineering Design Cost Prediction case, which was primarily developed by a single engineer in the business organization. The speed was, however, lower than in the two preceding cases. On the other hand, the Engineering Design Rework Reduction case, was of larger scope. It involved both vendors, IT representatives, and process stakeholders in an intensive process that ended up taking 16 weeks, without major results to show for it.
6 Discussion
In this section, we return to the research question, how can lightweight IT contribute to explorative BPM for embedded machine learning? ML, when embedded in business processes, has the potential to significantly improve business process performance by augmenting or automating decisions and enabling process redesign (Davenport, 2018; Enholm et al., 2021). Forward looking companies thus need to be able to explore the affordances of embedded ML as part of their explorative BPM activities. While lightweight IT has been proposed as a solution for exploring process innovation affordances of digital technologies in general (Schmiedel & vom Brocke, 2015; Bygstad & Øvrelid, 2020), the literature is unclear as to whether this is applicable to ML, traditionally considered a heavyweight technology.
Our findings suggest that for embedded ML projects to succeed as lightweight IT requires the co-presence of two enabling factors, i.e., loose coupling between heavyweight and lightweight IT and extensive use of building blocks in the development process. We first discuss loose coupling, then the use of building blocks, before we conclude how we contribute to the research on exploratory BPM.
6.1 Loose Coupling
Our case analysis shows how coupling, a property of the IT infrastructure, impacts process innovation latency. Building on previous research suggesting the use of lighter engineering for process innovation with digital technologies (Baiyere et al., 2020; Bygstad & Øvrelid, 2020), we find that tight coupling between lightweight and heavyweight IT reduces speed in exploratory innovation.
In the one case where coupling between heavyweight and lightweight IT was tight (Engineering Design Rework Reduction), the need to interact extensively with heavyweight IT processes and developers related to data extraction from the CAD system ended up acting as a bottleneck. This bottleneck significantly slowed down the whole project and rendered the use of Automated ML tools to speed up model development less impactful. The impact of coupling on speed in this case was particularly clear, as the first modeling iteration, which relied only on data sources that could be accessed independently of heavyweight IT resources, was much faster.
This is in line with the findings of Bygstad & Øvrelid, (2020), who identified loosely coupled interaction of lightweight and heavyweight IT as an enabler of successful process innovation. Tight coupling reduces the speed of innovation to that of heavyweight IT, which is slow due to its systematicism and focus on rigour (Bygstad, 2017). Additionally, it increases the scope and complexity of the innovation initiative by requiring the coordination of two widely different knowledge regimes. Lightweight and heavyweight IT systems need to interact as the heavyweight systems contain data and functionality necessary for most process innovations. Thus, the usage of lightweight technologies by themselves is necessary but not sufficient for speed unless accompanied by either no or loose coupling to heavyweight IT. This has implications for how the role of IT infrastructure in BPM is conceptualized. Supporting the claim of a need for more flexibility in IT infrastructure in digital age BPM (Baiyere et al., 2020), our findings suggest that IT infrastructure needs to take on dual roles. On the one hand, it needs to support efficient process execution as has been its traditional role. However, it also needs to act as an innovation platform by exposing data and capabilities for decoupled innovation activities. In our cases this was achieved through boundary resources that provided loosely coupled access to the heavyweight IT infrastructure, but also by means of new IT infrastructure, such as the data and deployment platforms.
6.2 Use of Building Blocks
Our analysis further suggests that the presence of loose coupling is not enough. Leveraging the concept of building blocks and conceptualizing innovation as recombination allowed us to conduct a more granular investigation of the development process (Henfridsson et al., 2018) and to go beyond the distinction between custom and packaged software. We found that extensive use of building blocks in the development process is required as well, as the data, model, and system component development tasks can otherwise become a considerable development effort. This was partly the case in the Engineering Design Cost Prediction case. The project relied on building blocks at the data level in the form of existing BI views and at system level in the form of the deployment platforms used to deploy the model and application. However, model development relied only on low-level building blocks and thus required custom development and experimentation to arrive at an acceptable model. In the Closed-loop Control of Machines and Data Quality Anomaly Detection cases, the use of building blocks for the model component allowed the projects to skip the model development step, thus contributing significantly to speeding up the process.
Examining the building blocks present in our cases in more depth, it becomes clear that they differ in nature and cluster into three categories: 1) boundary resources, 2) developer platforms, and 3) solution components. The boundary resources (Ghazawneh & Henfridsson, 2013), consisting of APIs and BI views, were essentially part of heavyweight IT and were what allowed the projects to interact in a loosely coupled fashion with heavyweight IT. We thus find support for internal boundary resources playing an important role in enabling innovation (Bygstad & Øvrelid, 2020). The developer platforms, namely a cloud data platform and an application hosting platform, provided on-demand access to infrastructural resources, such as storage and compute for deployment and development. This both prevented the innovation team from managing complex infrastructure and prevented tight coupling to the IT infrastructure teams. This finding supports existing research demonstrating the importance of mature data platforms for obtaining value from ML (Reis et al., 2020) and increasing development speed (Anand et al., 2016) and hints at the mechanisms behind these effects. The solution components (consisting of data pipelines, models, and systems) functioned to reduce custom development and skip steps in the ML process. The origin of these components varied. Some components were the result of previous internal development, other components were offered by cloud vendors, and finally, some of the lower-level components were open-source software. On the one hand, this underscores the complexity of ML and that there is indeed much more to ML than the model (Lavin et al., 2022; Ratner et al., 2019; Sculley et al., 2015), as emphasized in the engineering-focused stream on ML systems. On the other hand, the presence of building blocks at the model and system level suggests that the increasing technological maturity of ML is indeed making ML a lighter technology, as emphasized in the data democratization and Automated ML research streams (Hutter et al., 2019; Lefebvre et al., 2021).
Thus, we argue that it is the combination of loose coupling to heavyweight IT and the extensive use of building blocks that allowed for successful lightweight ML and fast exploration of process innovation affordances. It is certainly possible to be successful without the use of building blocks, but the initiatives are bound to be slower due to the increased scope and complexity of the development process. On the other hand, it is important to emphasize that the successful discovery of process innovation affordances is not guaranteed by using lightweight ML. Success is a result of the right combination of problem, data, model, and system, something to which lightweight ML does not contribute directly. It does, however, contribute to increasing the speed at which different combinations can be explored.
6.3 Contribution to the Research on Explorative BPM
Our study contributes by providing an empirical investigation of exploratory digital process innovation. First, our study provides insights into the opportunity assessment stage of exploratory digital process innovation with ML. Existing research on realizing explorative BPM has focused on support for realizing the opportunity identification stage (Grisold et al., 2022; Gross et al., 2021) and, to a lesser extent, the implementation phase (Baier et al., 2022) but has so far not addressed the opportunity assessment stage. It is in the opportunity assessment stage that the process innovation affordances of digital technologies are explored in more depth by turning the identified opportunities into PoCs. This exploration process is critical for digital technologies such as ML. Recent research has suggested that ML is a weakly structured technology and thus requires significant organizational effort to discover its affordances (Eley & Lyytinen, 2022). We found that this was indeed the case, as all four cases required technology development and experimentation, realized through the embedded ML development process, to discover and assess the process innovation affordances of ML. This exploration included adapting or grounding the general-purpose ML technology (Kemp, 2023) in the organizational context by curating data and experimenting with different configurations of ML. Whereas the configuration of ML happened in each project and was unique to the use case, data curation in the Closed-loop Control Case was the result of strategic process decision-making. In this case, acquiring the necessary data had required first establishing connectivity to manufacturing machines, which was a larger infrastructure and IT investment, and second, running experiments on machines in the R&D department to create data for the ML system. In the other three cases, data curation was a matter of exploring which of the data generated by existing processes that could be useful for the use case. Our findings thus suggest that ML implementation in BPM does require grounding (Kemp, 2023) and that this can sometimes take outset in data generated as a by-product of existing processes, whereas other use cases require creating or modifying processes to generate the data required for ML implementation.
Second, our study provides empirical insights into how exploratory process innovation initiatives are triggered. The four initiatives examined were all triggered in different ways based on the initiative of either business or IT stakeholders. What the initiatives had in common was the combination of 1) one or more stakeholders with a vision or an idea for how embedded ML could be used to improve a certain process and 2) the availability of resources to commit to the exploration process. In some cases, the resources required were modest, i.e., a single engineer who was allowed to work part-time on the project, whereas in other cases it required an R&D team or a larger project team of business, IT, and consultants. In contrast to the assumptions of existing work on explorative BPM (Grisold et al., 2022; Gross et al., 2021), the initiatives were not triggered as the result of top-down structured workshops but rather were of a more bottom-up nature, as is characteristic of digital innovation (Mendling et al., 2020). At the case organization, the main issue was not a shortage of ideas, but rather of technical resources needed to carry out the technology assessment and development work. An implication is that it would be fruitful for exploratory BPM research to consider how to account for and manage bottom-up initiatives to ensure that the right initiatives are resourced and that a process perspective is maintained.
Third, we contribute by demonstrating how the use of loose coupling and building blocks impacts process innovation latency. Innovation occurs not by inventing something completely new but rather by recombination of existing technologies and knowledge (Arthur, 2009). Using loose coupling and higher-level building blocks allows for higher speed in the innovation process, achieved by skipping technology development steps, and allows the focus to remain on the process affordances offered by the technology. This is compatible with the existing view of lighter engineering as best practice in process innovation, achieved by configuring standard and flexible technology (Schmiedel & vom Brocke, 2015; Baiyere et al., 2020; Bygstad & Øvrelid, 2020). We add nuance to this discussion by demonstrating that the use of building blocks (rather than standard technologies) also allows for fast innovation. A straightforward implication is that achieving high speed in explorative BPM is dependent on the maturity level of the technology, as building blocks are more likely to be available for more mature technologies. There is thus a trade-off between innovativeness and speed, and explorative BPM research needs to offer solutions that are able to handle exploration of both immature emergent technologies, as well as the use of more mature technologies in new ways. Zooming in on embedded ML, this means that there is a trade-off between predictive performance and innovation speed, as generic models, embedded in standard solutions, will most likely perform worse than custom developments (May et al., 2020).
To summarize, we show that lightweight IT can contribute to explorative BPM for embedded ML by significantly speeding up the opportunity assessment and technical implementation phases of the innovation process, thus reducing process innovation latency.
6.4 Implications for Practice
Our findings have practical implications for managers looking to explore the process affordances of ML. First, managers need to be aware of the distinction between lightweight and heavyweight ML and adjust their expectations and organization of exploratory activities accordingly. Lightweight ML initiatives can be run outside the traditional IT department using fast iterations, e.g., by collaborating with Data Science CoEs, vendors, or data scientists in business units. Heavyweight ML initiatives, on the other hand, are likely to require teaming up with the IT department and adopting a longer-term R&D perspective. All relevant initiatives will not be lightweight ML, as ML is still a relatively immature technology with high-level building blocks only existing for specific use cases, or as in the Closed-loop Control of Machines case, as the result of previous data science R&D. Process managers should therefore consider teaming up with internal data science competences to ensure their R&D activities have clear process relevance.
Second, managers looking to achieve fast exploration of the process innovation affordances of ML need to work together with IT and invest in building a loosely coupled IT infrastructure. The ability to deploy ML systems loosely coupled from heavyweight systems requires both self-service data access and self-service ML deployment infrastructure. Self-service data access can be realized by means of API-enabling heavyweight systems or by constructing data pipelines to transport heavyweight data to a data lake or data warehouse. However, as illustrated by the Engineering Design Loops Reduction case, vendor provided proprietary APIs might not cut it, as they often do not allow for true self-service data access. Self-service deployment platforms can be built internally or, as is commonly the case, acquired from cloud vendors (e.g., Databricks, Microsoft Azure, Google Cloud Platform, or Amazon AWS).
6.5 Limitations & Future Research
Our study is not without its limitations. First, the projects addressed were all concerned with opportunity-driven exploratory innovation of business processes, but they did not fit perfectly with the emerging conceptualization of explorative BPM. In addition to its characterization as opportunity-driven, explorative BPM is often associated with radical process innovation focused on novel value propositions (Grisold et al., 2022; Rosemann, 2014). The projects we examined, on the other hand, consisted of internally-focused innovations aimed at improving operations and most of the cases leaned towards incremental rather than radical innovation. Nonetheless, we argue the cases deviate considerably from the traditional and reactive exploitative BPM and are thus closer in spirit to explorative BPM. We suggest future research further clarify the concept of explorative BPM, making it clear where opportunity and technology-driven but internally-focused innovation fits, as our empirical engagements show that it is a phenomenon receiving significant attention in practice.
We also acknowledge that our theorizing is based on a selection of projects from our ongoing action-oriented work in a single case organization, thus limiting its generalizability. Selecting among projects that we were engaged in facilitated an in-depth and detailed understanding of the phenomena under study, including both technical and organizational aspects, and allowed us to go beneath the surface and provide an insider perspective on the use of lightweight ML for process innovation. It does, however, come at the cost of the representativeness of the projects selected. Further research should test whether the co-presence of loose coupling and extensive use of building blocks are necessary for successful lightweight ML projects in different organizations.
7 Conclusion
In this study, we set out to investigate how lightweight IT can contribute to explorative BPM for embedded ML. We presented and analyzed four cases that attempted to treat ML as lightweight IT with different degrees of success. To assist us in the analysis, we relied on an analytical framework that leveraged the concepts of (i) coupling (Weick, 1976), specifically between lightweight and heavyweight IT (Bygstad, 2017), and (ii) building blocks, i.e., the extent of use of existing socio-technical components in the development of solutions.
Our analysis of four cases of embedded ML in a large Danish manufacturer demonstrated that a lightweight approach can considerably speed up assessment and technology implementation of ML, thus contributing to the fast exploration of process innovation affordances. The lightweight approach is, however, not always feasible, as it requires the presence of two enabling factors. First, it requires loose coupling between the exploratory initiative and the execution-focused organization, which in turn requires a loosely coupled IT infrastructure. Second, it requires that the exploratory initiative makes use of building blocks, thus reducing the need for extensive custom development and engineering. With a lightweight approach, the focus is moved from the technology towards the process and its’ improvement, and while the existing technological maturity level of ML does not always allow for a lightweight approach, the rapid pace of development suggests that it will be increasingly possible in the near future.
Data Availability
The data generated during and/or analysed during the current study cannot be made publicly available due to confidentiality agreements made with the participating case organization to protect its commercial interests. Further information and details regarding the data can be obtained from the corresponding author upon request.
References
Ågerfalk, P. J. (2010). Getting pragmatic. European Journal of Information Systems, 19(3), 251–256. https://doi.org/10.1057/ejis.2010.22
Anand, A., Sharma, R., & Coltman, T. (2016). Four Steps to Realizing Business Value from Digital Data Streams. MIS Quarterly Executive, 15(4). https://aisel.aisnet.org/misqe/vol15/iss4/3
Arthur, W. B. (2009). The nature of technology: what it is and how it evolves. Simon and Schuster.
Baier, M.-S., Lockl, J., Röglinger, M., & Weidlich, R. (2022). Success factors of process digitalization projects – insights from an exploratory study. Business Process Management Journal, 28(2), 325–347. https://doi.org/10.1108/BPMJ-07-2021-0484
Baiyere, A., Salmela, H., & Tapanainen, T. (2020). Digital transformation and the new logics of business process management. European Journal of Information Systems, 29(3), 238–259. https://doi.org/10.1080/0960085X.2020.1718007
Benbya, H., Pachidi, S., & Jarvenpaa, S. L. (2021). Special issue editorial: artificial intelligence in organizations: implications for information systems research. Journal of the Association for Information Systems, 22(2), 281–303. https://doi.org/10.17705/1jais.00662
Benner, M. J., & Tushman, M. L. (2003). Exploitation, Exploration, and Process Management: The Productivity Dilemma Revisited. The Academy of Management Review, 28(2), 238–256. https://doi.org/10.2307/30040711
Berente, N., Gu, B., Recker, J., & Santhanam, R. (2021). Managing artificial intelligence. MIS Quarterly, 45(3), 1433–1450.
Braa, K., & Vidgen, R. (1999). Interpretation, intervention, and reduction in the organizational laboratory: A framework for in-context information system research. Accounting, Management and Information Technologies, 9(1), 25–47. https://doi.org/10.1016/S0959-8022(98)00018-6
Breck, E., Polyzotis, N., Roy, S., Whang, S. E., & Zinkevich, M. (2019). Data validation for machine learning. Proceedings of Machine Learning and Systems, 1, 14.
Bygstad, B. (2017). Generative innovation: A comparison of lightweight and heavyweight IT. Journal of Information Technology, 32(2), 180–193. https://doi.org/10.1057/jit.2016.15
Bygstad, B., & Øvrelid, E. (2020). Architectural alignment of process innovation and digital infrastructure in a high-tech hospital. European Journal of Information Systems, 29(3), 220–237. https://doi.org/10.1080/0960085X.2020.1728201
Davenport, T. H. (2018). From analytics to artificial intelligence. Journal of Business Analytics, 1(2), 73–80. https://doi.org/10.1080/2573234X.2018.1543535
Davenport, T. H., & Short, J. E. (1990). The new industrial engineering: Information technology and business process redesign. Sloan Management Review, 31(4), 11–27.
Davenport, T., & Malone, K. (2021). Deployment as a critical business data science discipline. Harvard Data Science Review, 3(1).
Davenport, T. H., Harris, J. G., & Morison, R. (2010). Analytics at work: Smarter decisions, better results. Harvard Business Press.
Dubois, A., & Gadde, L.-E. (2002). Systematic combining: An abductive approach to case research. Journal of Business Research, 55(7), 553–560. https://doi.org/10.1016/S0148-2963(00)00195-8
Dumas, M., La Rosa, M., Mendling, J., & Reijers, H. A. (2013). Fundamentals of business process management (Vol. 1). Springer.
Eley, T., & Lyytinen, K. (2022). Industry 4.0 Implementation: Novel Issues and Directions. Proceedings of the 55th Hawaii International Conference on System Sciences. Hawaii International Conference on System Sciences. https://doi.org/10.24251/HICSS.2022.622
Enholm, I. M., Papagiannidis, E., Mikalef, P., & Krogstie, J. (2021). Artificial Intelligence and Business Value: A Literature Review. Information Systems Frontiers, 24, 1709–1734. https://doi.org/10.1007/s10796-021-10186-w
Ghazawneh, A., & Henfridsson, O. (2013). Balancing platform control and external contribution in third-party development: The boundary resources model. Information Systems Journal, 23(2), 173–192. https://doi.org/10.1111/j.1365-2575.2012.00406.x
Goldkuhl, G. (2012). Pragmatism vs interpretivism in qualitative information systems research. European Journal of Information Systems, 21(2), 135–146. https://doi.org/10.1057/ejis.2011.54
Grisold, T., Groß, S., Stelzl, K., vom Brocke, J., Mendling, J., Röglinger, M., & Rosemann, M. (2022). The Five Diamond Method for Explorative Business Process Management. Business & Information Systems Engineering, 64(2), 149–166. https://doi.org/10.1007/s12599-021-00703-1
Grisold, T., Gross, S., Röglinger, M., Stelzl, K., & vom Brocke, J. (2019). Exploring Explorative BPM - Setting the Ground for Future Research. In T. Hildebrandt, B. F. van Dongen, M. Röglinger, & J. Mendling (Eds.), Business Process Management (Vol. 11675, pp. 23–31). Springer International Publishing. https://doi.org/10.1007/978-3-030-26619-6_4
Grønsund, T., & Aanestad, M. (2020). Augmenting the algorithm: Emerging human-in-the-loop work configurations. The Journal of Strategic Information Systems, 29(2), 101614. https://doi.org/10.1016/j.jsis.2020.101614
Gross, S., Stelzl, K., Grisold, T., Mendling, J., Röglinger, M., & Vom, B. J. (2021). The Business Process Design Space for exploring process redesign alternatives. Business Process Management Journal, 27(8), 25–56. https://doi.org/10.1108/BPMJ-03-2020-0116
Henfridsson, O., Nandhakumar, J., Scarbrough, H., & Panourgias, N. (2018). Recombination in the open-ended value landscape of digital innovation. Information and Organization, 28(2), 89–100. https://doi.org/10.1016/j.infoandorg.2018.03.001
Hutter, F., Kotthoff, L., & Vanschoren, J. (Eds.). (2019). Automated Machine Learning: Methods, Systems, Challenges. Springer International Publishing. https://doi.org/10.1007/978-3-030-05318-5
Kemp, A. (2023). Competitive Advantages through Artificial Intelligence: Toward a Theory of Situated AI. Academy of Management Review. https://journals.aom.org/doi/abs/https://doi.org/10.5465/amr.2020.0205
Kerpedzhiev, G. D., König, U. M., Röglinger, M., & Rosemann, M. (2021). An Exploration into Future Business Process Management Capabilities in View of Digitalization. Business & Information Systems Engineering, 63(2), 83–96. https://doi.org/10.1007/s12599-020-00637-0
Kunz, P. C., Jussupow, E., Spohrer, K., & Heinzl, A. (2022). How the Application of Machine Learning Systems Changes Business Processes: A Multiple Case Study. ECIS 2022 Proceedings. Thirtieth European Conference on Information Systems.
Lang, K. R., Misic, V. B., & Zhao, L. J. (2015). Special section on business process analytics. Information Systems Frontiers, 17(6), 1191–1194. https://doi.org/10.1007/s10796-015-9610-1
Lavin, A., Gilligan-Lee, C. M., Visnjic, A., Ganju, S., Newman, D., Ganguly, S., Lange, D., Baydin, A. G., Sharma, A., Gibson, A., Zheng, S., Xing, E. P., Mattmann, C., Parr, J., & Gal, Y. (2022). Technology readiness levels for machine learning systems. Nature Communications, 13(1), 6039. https://doi.org/10.1038/s41467-022-33128-9
Lefebvre, H., Legner, C., & Fadler, M. (2021). Data democratization: Toward a deeper understanding. ICIS 2021 Proceedings. International Conference of Information Systems.
Martínez-Plumed, F., Contreras-Ochando, L., Ferri, C., Hernández-Orallo, J., Kull, M., Lachiche, N., Ramírez-Quintana, M. J., & Flach, P. (2019). CRISP-DM twenty years later: from data mining processes to data science trajectories. IEEE Transactions on Knowledge and Data Engineering, 33(8), 3048–3061. https://doi.org/10.1109/TKDE.2019.2962680
May, A., Sagodi, A., Dremel, C., & van Giffen, B. (2020). Realizing Digital Innovation from Artificial Intelligence. ICIS 2020 Proceedings. Forty-First International Conference on Information Systems.
Mendling, J., Pentland, B. T., & Recker, J. (2020). Building a complementary agenda for business process management and digital innovation. European Journal of Information Systems, 29(3), 208–219. https://doi.org/10.1080/0960085X.2020.1755207
Microsoft. (2023). What is the Team Data Science Process? Microsoft. https://learn.microsoft.com/en-us/azure/architecture/data-science-process/overview
Paleyes, A., Urma, R.-G., & Lawrence, N. D. (2022). Challenges in Deploying Machine Learning: A Survey of Case Studies. ACM Computing Surveys, 3533378. https://doi.org/10.1145/3533378
Phillips-Wren, G., Daly, M., & Burstein, F. (2021). Reconciling business intelligence, analytics and decision support systems: More data, deeper insight. Decision Support Systems, 146, 113560. https://doi.org/10.1016/j.dss.2021.113560
Poll, R., Polyvyanyy, A., Rosemann, M., Röglinger, M., & Rupprecht, L. (2018). Process Forecasting: Towards Proactive Business Process Management. In M. Weske, M. Montali, I. Weber, & J. vom Brocke (Eds.), Business Process Management (Vol. 11080, pp. 496–512). Springer International Publishing. https://doi.org/10.1007/978-3-319-98648-7_29
Ratner, A., Alistarh, D., Alonso, G., Andersen, D. G., Bailis, P., Bird, S., Carlini, N., Catanzaro, B., Chayes, J., Chung, E., Dally, B., Dean, J., Dhillon, I. S., Dimakis, A., Dubey, P., Elkan, C., Fursin, G., Ganger, G. R., Getoor, L., … Talwalkar, A. (2019). MLSys: The New Frontier of Machine Learning Systems (arXiv:1904.03257). arXiv. http://arxiv.org/abs/1904.03257
Reis, C., Ruivo, P., Oliveira, T., & Faroleiro, P. (2020). Assessing the drivers of machine learning business value. Journal of Business Research, 117, 232–243. https://doi.org/10.1016/j.jbusres.2020.05.053
Robey, D., & Taylor, W. T. F. (2018). Engaged Participant Observation: An Integrative Approach to Qualitative Field Research for Practitioner-Scholars. Engaged Management ReView, 2(1). https://doi.org/10.28953/2375-8643.1028
Rosemann, M. (2014). Proposals for Future BPM Research Directions. In C. Ouyang & J.-Y. Jung (Eds.), Asia Pacific Business Process Management (Vol. 181, pp. 1–15). Springer International Publishing. https://doi.org/10.1007/978-3-319-08222-6_1
Sætre, A. S., & Van De Ven, A. (2021). Generating Theory by Abduction. Academy of Management Review, 46(4), 684–701. https://doi.org/10.5465/amr.2019.0233
Schmiedel, T., & vom Brocke, J. (2015). Business Process Management: Potentials and Challenges of Driving Innovation. In J. vom Brocke & T. Schmiedel (Eds.), BPM - Driving Innovation in a Digital World (pp. 3–15). Springer International Publishing. https://doi.org/10.1007/978-3-319-14430-6_1
Sculley, D., Holt, G., Golovin, D., Davydov, E., Phillips, T., Ebner, D., Chaudhary, V., Young, M., Crespo, J.-F., & Dennison, D. (2015). Hidden Technical Debt in Machine Learning Systems. Advances in Neural Information Processing Systems, 28. https://proceedings.neurips.cc/paper/2015/hash/86df7dcfd896fcaf2674f757a2463eba-Abstract.html
Sedera, D., Lokuge, S., Grover, V., Sarker, S., & Sarker, S. (2016). Innovating with enterprise systems and digital platforms: A contingent resource-based theory view. Information & Management, 53(3), 366–379. https://doi.org/10.1016/j.im.2016.01.001
Sein, Henfridsson, Purao, Rossi, & Lindgren. (2011). Action design research. MIS Quarterly, 35(1), 37. https://doi.org/10.2307/23043488
Simon, H. (1996). The Sciences of the Artificial (3rd ed.). MIT Press.
Teinemaa, I., Dumas, M., Rosa, M. L., & Maggi, F. M. (2019). Outcome-oriented predictive process monitoring: review and benchmark. ACM Transactions on Knowledge Discovery from Data, 13(2), 1–57. https://doi.org/10.1145/3301300
Uzunalioglu, H., Cao, J., Phadke, C., Lehmann, G., Akyamac, A., He, R., Lee, J., & Able, M. (2019). Augmented Data Science: Towards Industrialization and Democratization of Data Science (arXiv:1909.05682). arXiv. http://arxiv.org/abs/1909.05682
Van de Ven, A. H. (2007). Engaged scholarship: A guide for organizational and social research. Oxford University Press on Demand.
Van Der Aalst, W. (2012). Process mining: overview and opportunities. ACM Transactions on Management Information Systems, 3(2), 1–17. https://doi.org/10.1145/2229156.2229157
Weick, K. E. (1976). Educational organizations as loosely coupled systems. Administrative Science Quarterly, 21(1), 1–19. https://doi.org/10.2307/2391875
Wirth, R., & Hipp, J. (2000). CRISP-DM: Towards a Standard Process Model for Data Mining. Proceedings of the 4th International Conference on the Practical Applications of Knowledge Discovery and Data Mining, 29–40.
Funding
Open access funding provided by Aalborg University The first author received funding from Manufacturing Academy of Denmark under the MADE FAST research and innovation programme (funding nr.: 9090-00002B) to support the research that led to this article.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Competing Interests
The authors have no competing interests to declare that are relevant to the content of this article.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Bojer, C.S., Bygstad, B. & Øvrelid, E. Speeding up Explorative BPM with Lightweight IT: the Case of Machine Learning. Inf Syst Front (2024). https://doi.org/10.1007/s10796-024-10474-1
Accepted:
Published:
DOI: https://doi.org/10.1007/s10796-024-10474-1